搜索到
113
篇与
的结果
-
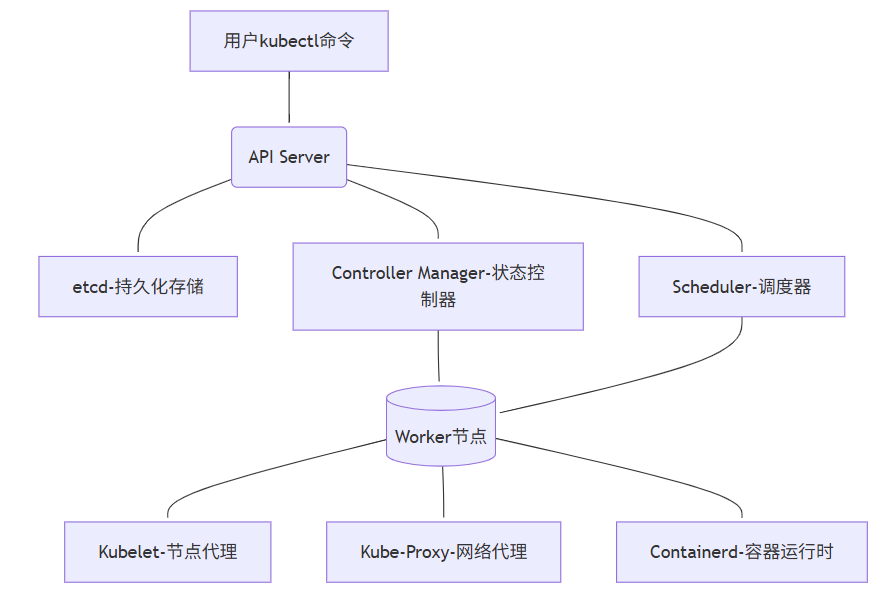
 K8s五大核心组件详解 居中 居右 颜色大小K8s不是"黑盒子" 一张图看懂核心架构先说个残酷真相:90%的K8s运维问题,根源在于不了解控制平面。就像修车只懂换轮胎,却不懂发动机原理。K8s架构全景图(简化实用版)💡 核心认知:K8s不是一组独立组件,而是一个精密协作的有机体。一个Pod的创建流程:用户指令 → API Server验证 → etcd持久化 → Controller创建资源 → Scheduler分配节点 → Kubelet启动容器五大核心组件:从"知道名字"到"摸透脾性"1. API Server:集群的"咽喉要道" 真实痛点:"为什么执行kubectl命令时卡住不动?为什么集群突然无法创建新资源?"工作原理(运维视角):• 所有操作的唯一入口(包括kubectl、控制器、调度器)• 不是简单的代理,而是认证/授权/准入控制的三重门神• 与etcd的交互是性能瓶颈关键关键参数(生产环境亲测):# kube-apiserver.yaml command: - kube-apiserver - --max-requests-inflight=1500 # 默认400,高负载集群必调 - --max-mutating-requests-inflight=500 # 写操作队列 - --etcd-servers=https://etcd1:2379,https://etcd2:2379 # etcd集群 - --request-timeout=1m # 防止客户端长时间占用故障排查锦囊:当API响应变慢时,先看这些指标:# 1. 查看API Server请求延迟 kubectl get --raw /metrics | grep apiserver_request_duration_seconds_bucket # 2. 检查活跃连接数 netstat -ant | grep ':6443' | wc -l # 6443是API Server端口 # 3. 紧急情况:重启API Server(需谨慎) systemctl restart kube-apiserver📌 血泪教训:曾因某次发布,一个错误的CRD定义导致API Server CPU 100%。根源:CRD验证逻辑过于复杂,每个请求都执行全量校验。解决:使用--runtime-config=api/all=false临时禁用问题API组。2. etcd:集群的"心脏起搏器" 真实痛点:"集群操作突然变卡,但节点和Pod看起来正常""etcd数据目录突然暴涨,磁盘空间告急"工作原理(运维视角):• 不只是KV存储,更是整个集群状态的唯一真相源• 使用Raft协议保证数据一致性(奇数节点,3/5/7)• 写操作必须经过Leader,读操作可从Follower获取etcd性能调优关键:# 1. 必须使用SSD磁盘!机械盘是性能杀手 mount -t xfs -o noatime,nodiratime,logbsize=256k /dev/sdb1 /var/lib/etcd # 2. 定期碎片整理(每月一次) etcdctl defrag --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key # 3. 关键监控指标 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.01"} # 99%请求应在10ms内完成 etcd_mvcc_db_total_size_in_bytes # 数据库大小灾难恢复实战:# 1. 备份(每天凌晨执行) ETCDCTL_API=3 etcdctl --endpoints=$ENDPOINTS snapshot save snapshot.db # 2. 恢复(灾难场景) ETCDCTL_API=3 etcdctl snapshot restore snapshot.db \ --name etcd1 \ --initial-cluster "etcd1=http://10.0.0.1:2380,etcd2=http://10.0.0.2:2380" \ --initial-cluster-token my-etcd-token \ --initial-advertise-peer-urls http://10.0.0.1:2380 # 3. 重启etcd服务 systemctl restart etcd 💡 我们的真实案例:一次大促前,etcd磁盘IO延迟从2ms飙升到200ms。排查过程:1.iostat -dx 1 发现%util=100%2.etcd_disk_backend_commit_duration_seconds 指标异常3.分析发现某团队在频繁更新ConfigMap(每秒50次)解决:限制客户端QPS + 合并ConfigMap更新3. Controller Manager:集群的"自动驾驶仪" 真实痛点:"Deployment配置了3副本,但只运行了2个Pod""节点宕机后,Pod没有自动迁移到其他节点"核心机制(运维视角):• 不是单个组件,而是多个控制器的集合(Deployment、Node、Endpoint等)• 工作模式:Informer Loop(List-Watch-Process)• 每个控制器独立工作,但共享API Server连接关键控制器职责:控制器职责常见问题Deployment Controller管理ReplicaSet和Pod无法扩缩容Node Controller监控节点状态,标记NotReady节点状态异常Endpoint Controller同步Service和Pod端点Service无法访问PodNamespace Controller清理已删除命名空间的资源命名空间卡在Terminating性能优化实战:# kube-controller-manager.yaml command: - kube-controller-manager - --concurrent-deployment-syncs=20 # 默认5,并行处理Deployment - --node-monitor-grace-period=40s # 节点失联容忍时间 - --pod-eviction-timeout=5m0s # 节点NotReady后驱逐Pod等待时间故障排查命令:# 1. 查看控制器工作队列 kubectl get --raw /metrics | grep workqueue_queue_duration_seconds # 2. 诊断Node Controller问题 kubectl get events --sort-by=.metadata.creationTimestamp | grep -i node # 3. 强制同步资源(紧急恢复) # 注意:需在master节点执行 curl -k -v -XPATCH \ -H "Accept: application/json, */*" \ -H "Content-Type: application/strategic-merge-patch+json" \ -H "Authorization: Bearer $(cat /var/run/secrets/kubernetes.io/serviceaccount/token)" \ https://kubernetes.default.svc/api/v1/namespaces/default/deployments/my-app/status \ --data '{"status":{"observedGeneration":0}}'📌 踩坑实录:一次版本升级后,所有Deployment无法扩缩容。现象:kubectl describe deployment显示"Progressing"但无变化真相:Controller Manager与API Server版本不兼容教训:永远先升级控制平面,再升级节点;永远不要跳过次要版本4. Scheduler:集群的"资源分配大师" 真实痛点:"新Pod一直卡在Pending状态""节点资源明明充足,但Scheduler不调度"调度过程揭秘(运维视角):1. 过滤阶段(Filtering):排除不满足条件的节点(资源不足、污点不匹配等)2. 打分阶段(Scoring):为剩余节点打分(资源均衡、亲和性等)3. 绑定阶段(Binding):选择最高分节点,通知API Server调度器性能调优:# kube-scheduler.yaml apiVersion: kubescheduler.config.k8s.io/v1beta3 kind: KubeSchedulerConfiguration profiles: - schedulerName: default-scheduler plugins: score: disabled: - name: NodeResourcesLeastAllocated # 禁用低效插件 enabled: - name: NodeResourcesBalancedAllocation weight: 2 filter: enabled: - name: PodTopologySpread诊断Pending Pod的终极命令:# 1. 查看调度失败原因 kubectl get events --field-selector involvedObject.name=my-pod -n my-namespace # 2. 详细诊断(关键!) kubectl describe pod my-pod | grep -A 10 "Events:" # 3. 模拟调度过程 kubectl get --raw "/apis/scheduling.k8s.io/v1/priorityclasses"💡 实战案例:我们曾遇到Pod卡在Pending,但节点资源充足。排查:• kubectl describe pod显示"Tolerates: node.kubernetes.io/not-ready:NoExecute"• 发现节点有临时污点解决:tolerations: - key: "node.kubernetes.io/not-ready" operator: "Exists" effect: "NoExecute" tolerationSeconds: 300 # 等待300秒后驱逐5. 工作节点组件:集群的"一线工人" 三剑客职责:• Kubelet:节点的"管家",管理Pod生命周期• Kube-Proxy:节点的"交通警察",维护Service网络规则• Containerd:节点的"发动机",运行容器Kubelet关键优化:# /var/lib/kubelet/config.yaml apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration maxPods: 110 # 默认110,根据节点规格调整 imageGCHighThresholdPercent: 85 # 磁盘使用超过85%清理镜像 imageGCLowThresholdPercent: 80 serializeImagePulls: false # 并行拉取镜像Kube-Proxy模式选择:模式优点缺点适用场景iptables稳定,兼容性好规则复杂时性能下降小规模集群(<100节点)ipvs高性能,连接复用需要内核支持大规模集群(>100节点)切换到ipvs模式:# 1. 检查内核支持 grep -e ipvs /lib/modules/$(uname -r)/modules.builtin # 2. 修改kube-proxy配置 kubectl edit configmap kube-proxy -n kube-system # mode: ipvs # 3. 重启kube-proxy kubectl delete pod -l k8s-app=kube-proxy -n kube-system📌 血泪教训:一次大促,Node节点突然NotReady。监控发现:Kubelet PLEG(Pod Lifecycle Event Generator)延迟>10s(正常<100ms)根因:某应用频繁创建/销毁临时容器(每秒20+)解决:临时:增加Kubelet资源限制--kube-reserved=cpu=500m,memory=1Gi长期:重构应用,避免高频创建Pod集群监控:给每个组件装上"心电图"核心监控指标清单(运维必备)组件关键指标告警阈值诊断命令API Serverrequest_duration_secondsP99> 1skubectl get --raw /metricsetcdwal_fsync_duration_seconds> 100msetcdctl endpoint statusSchedulerscheduling_duration_seconds> 10skubectl logs -l component=kube-schedulerKubeletpleg_relist_interval_seconds> 10sjournalctl -u kubeletNodememory.available< 10%kubectl describe node快速诊断脚本(保存为check-cluster.sh):#!/bin/bash echo "=== 集群健康检查报告 ($(date)) ===" # 1. 节点状态 echo -e "\n[1] 节点状态:" kubectl get nodes -o wide # 2. Pending的Pod echo -e "\n[2] Pending状态的Pod:" kubectl get pods --all-namespaces --field-selector=status.phase=Pending # 3. API Server延迟 echo -e "\n[3] API Server关键指标:" kubectl get --raw /metrics | grep -E "apiserver_request_duration_seconds|apiserver_current_inflight_requests" # 4. etcd健康状态 echo -e "\n[4] etcd健康检查 (需要在master节点执行):" if [ -x "$(command -v etcdctl)" ]; then ETCDCTL_API=3 etcdctl endpoint health --cluster fi echo -e "\n=== 诊断完成 ==="💡 专业建议:为每个组件设置黄金指标告警:• API Server: 5xx错误率 > 1%• etcd: 写入延迟 > 100ms• Scheduler: 调度队列深度 > 100这些告警比"节点宕机"提前30分钟发现问题!血泪教训:我们踩过的5个致命陷阱陷阱1:etcd版本与K8s不匹配• 现象:集群随机出现资源创建失败• 根因:K8s 1.22要求etcd 3.5+,但我们用了3.4• 解决:严格遵循版本兼容矩阵陷阱2:Controller Manager未配置leader选举• 现象:Controller Manager重启后,所有Deployment卡住• 解决:--leader-elect=true --leader-elect-lease-duration=15s 陷阱3:Kubelet证书未自动轮换• 现象:节点突然NotReady,日志报"x509证书过期"• 预防:--rotate-certificates=true --feature-gates=RotateKubeletServerCertificate=true 陷阱4:Scheduler资源不足• 现象:高负载时Pod调度延迟从1s飙升到60s+• 优化:resources: requests: cpu: 500m memory: 512Mi limits: cpu: 1 memory: 1Gi陷阱5:忽略组件间网络QoS• 现象:API Server与etcd通信偶尔超时• 解决:为关键组件配置网络优先级tc qdisc add dev eth0 root handle 1: htb tc class add dev eth0 parent 1: classid 1:1 htb rate 100mbit tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 2379 0xffff flowid 1:1从"救火队员"到"集群医生":我们的蜕变能力优化前优化后故障定位时间2-4小时5-15分钟集群稳定性每月3-5次严重故障连续180天无P0事故运维信心"重启试试""我知道问题在哪""以前看到Pending Pod就紧张,现在先看kubectl get events,基本5分钟定位问题。"行动指南:今晚就能做的3件事1. 今晚:在你的集群执行kubectl get --raw /metrics | grep apiserver_request_duration_seconds如果P99 > 500ms,说明API Server需要优化2. 明天:检查etcd磁盘IO性能iostat -dx 1 | grep etcd_device确保%util < 70%,await < 10ms3. 本周:为你的测试集群模拟一次etcd故障# 警告:仅在测试环境执行! systemctl stop etcd watch kubectl get nodes # 观察节点状态变化 systemctl start etcd # 恢复记住:真正的K8s高手,不是从不遇到问题,而是知道问题出在哪一层。从今天起,当集群异常时,先问自己:"这是API Server的问题?etcd的问题?控制器的问题?调度器的问题?还是节点的问题?"
K8s五大核心组件详解 居中 居右 颜色大小K8s不是"黑盒子" 一张图看懂核心架构先说个残酷真相:90%的K8s运维问题,根源在于不了解控制平面。就像修车只懂换轮胎,却不懂发动机原理。K8s架构全景图(简化实用版)💡 核心认知:K8s不是一组独立组件,而是一个精密协作的有机体。一个Pod的创建流程:用户指令 → API Server验证 → etcd持久化 → Controller创建资源 → Scheduler分配节点 → Kubelet启动容器五大核心组件:从"知道名字"到"摸透脾性"1. API Server:集群的"咽喉要道" 真实痛点:"为什么执行kubectl命令时卡住不动?为什么集群突然无法创建新资源?"工作原理(运维视角):• 所有操作的唯一入口(包括kubectl、控制器、调度器)• 不是简单的代理,而是认证/授权/准入控制的三重门神• 与etcd的交互是性能瓶颈关键关键参数(生产环境亲测):# kube-apiserver.yaml command: - kube-apiserver - --max-requests-inflight=1500 # 默认400,高负载集群必调 - --max-mutating-requests-inflight=500 # 写操作队列 - --etcd-servers=https://etcd1:2379,https://etcd2:2379 # etcd集群 - --request-timeout=1m # 防止客户端长时间占用故障排查锦囊:当API响应变慢时,先看这些指标:# 1. 查看API Server请求延迟 kubectl get --raw /metrics | grep apiserver_request_duration_seconds_bucket # 2. 检查活跃连接数 netstat -ant | grep ':6443' | wc -l # 6443是API Server端口 # 3. 紧急情况:重启API Server(需谨慎) systemctl restart kube-apiserver📌 血泪教训:曾因某次发布,一个错误的CRD定义导致API Server CPU 100%。根源:CRD验证逻辑过于复杂,每个请求都执行全量校验。解决:使用--runtime-config=api/all=false临时禁用问题API组。2. etcd:集群的"心脏起搏器" 真实痛点:"集群操作突然变卡,但节点和Pod看起来正常""etcd数据目录突然暴涨,磁盘空间告急"工作原理(运维视角):• 不只是KV存储,更是整个集群状态的唯一真相源• 使用Raft协议保证数据一致性(奇数节点,3/5/7)• 写操作必须经过Leader,读操作可从Follower获取etcd性能调优关键:# 1. 必须使用SSD磁盘!机械盘是性能杀手 mount -t xfs -o noatime,nodiratime,logbsize=256k /dev/sdb1 /var/lib/etcd # 2. 定期碎片整理(每月一次) etcdctl defrag --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key # 3. 关键监控指标 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.01"} # 99%请求应在10ms内完成 etcd_mvcc_db_total_size_in_bytes # 数据库大小灾难恢复实战:# 1. 备份(每天凌晨执行) ETCDCTL_API=3 etcdctl --endpoints=$ENDPOINTS snapshot save snapshot.db # 2. 恢复(灾难场景) ETCDCTL_API=3 etcdctl snapshot restore snapshot.db \ --name etcd1 \ --initial-cluster "etcd1=http://10.0.0.1:2380,etcd2=http://10.0.0.2:2380" \ --initial-cluster-token my-etcd-token \ --initial-advertise-peer-urls http://10.0.0.1:2380 # 3. 重启etcd服务 systemctl restart etcd 💡 我们的真实案例:一次大促前,etcd磁盘IO延迟从2ms飙升到200ms。排查过程:1.iostat -dx 1 发现%util=100%2.etcd_disk_backend_commit_duration_seconds 指标异常3.分析发现某团队在频繁更新ConfigMap(每秒50次)解决:限制客户端QPS + 合并ConfigMap更新3. Controller Manager:集群的"自动驾驶仪" 真实痛点:"Deployment配置了3副本,但只运行了2个Pod""节点宕机后,Pod没有自动迁移到其他节点"核心机制(运维视角):• 不是单个组件,而是多个控制器的集合(Deployment、Node、Endpoint等)• 工作模式:Informer Loop(List-Watch-Process)• 每个控制器独立工作,但共享API Server连接关键控制器职责:控制器职责常见问题Deployment Controller管理ReplicaSet和Pod无法扩缩容Node Controller监控节点状态,标记NotReady节点状态异常Endpoint Controller同步Service和Pod端点Service无法访问PodNamespace Controller清理已删除命名空间的资源命名空间卡在Terminating性能优化实战:# kube-controller-manager.yaml command: - kube-controller-manager - --concurrent-deployment-syncs=20 # 默认5,并行处理Deployment - --node-monitor-grace-period=40s # 节点失联容忍时间 - --pod-eviction-timeout=5m0s # 节点NotReady后驱逐Pod等待时间故障排查命令:# 1. 查看控制器工作队列 kubectl get --raw /metrics | grep workqueue_queue_duration_seconds # 2. 诊断Node Controller问题 kubectl get events --sort-by=.metadata.creationTimestamp | grep -i node # 3. 强制同步资源(紧急恢复) # 注意:需在master节点执行 curl -k -v -XPATCH \ -H "Accept: application/json, */*" \ -H "Content-Type: application/strategic-merge-patch+json" \ -H "Authorization: Bearer $(cat /var/run/secrets/kubernetes.io/serviceaccount/token)" \ https://kubernetes.default.svc/api/v1/namespaces/default/deployments/my-app/status \ --data '{"status":{"observedGeneration":0}}'📌 踩坑实录:一次版本升级后,所有Deployment无法扩缩容。现象:kubectl describe deployment显示"Progressing"但无变化真相:Controller Manager与API Server版本不兼容教训:永远先升级控制平面,再升级节点;永远不要跳过次要版本4. Scheduler:集群的"资源分配大师" 真实痛点:"新Pod一直卡在Pending状态""节点资源明明充足,但Scheduler不调度"调度过程揭秘(运维视角):1. 过滤阶段(Filtering):排除不满足条件的节点(资源不足、污点不匹配等)2. 打分阶段(Scoring):为剩余节点打分(资源均衡、亲和性等)3. 绑定阶段(Binding):选择最高分节点,通知API Server调度器性能调优:# kube-scheduler.yaml apiVersion: kubescheduler.config.k8s.io/v1beta3 kind: KubeSchedulerConfiguration profiles: - schedulerName: default-scheduler plugins: score: disabled: - name: NodeResourcesLeastAllocated # 禁用低效插件 enabled: - name: NodeResourcesBalancedAllocation weight: 2 filter: enabled: - name: PodTopologySpread诊断Pending Pod的终极命令:# 1. 查看调度失败原因 kubectl get events --field-selector involvedObject.name=my-pod -n my-namespace # 2. 详细诊断(关键!) kubectl describe pod my-pod | grep -A 10 "Events:" # 3. 模拟调度过程 kubectl get --raw "/apis/scheduling.k8s.io/v1/priorityclasses"💡 实战案例:我们曾遇到Pod卡在Pending,但节点资源充足。排查:• kubectl describe pod显示"Tolerates: node.kubernetes.io/not-ready:NoExecute"• 发现节点有临时污点解决:tolerations: - key: "node.kubernetes.io/not-ready" operator: "Exists" effect: "NoExecute" tolerationSeconds: 300 # 等待300秒后驱逐5. 工作节点组件:集群的"一线工人" 三剑客职责:• Kubelet:节点的"管家",管理Pod生命周期• Kube-Proxy:节点的"交通警察",维护Service网络规则• Containerd:节点的"发动机",运行容器Kubelet关键优化:# /var/lib/kubelet/config.yaml apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration maxPods: 110 # 默认110,根据节点规格调整 imageGCHighThresholdPercent: 85 # 磁盘使用超过85%清理镜像 imageGCLowThresholdPercent: 80 serializeImagePulls: false # 并行拉取镜像Kube-Proxy模式选择:模式优点缺点适用场景iptables稳定,兼容性好规则复杂时性能下降小规模集群(<100节点)ipvs高性能,连接复用需要内核支持大规模集群(>100节点)切换到ipvs模式:# 1. 检查内核支持 grep -e ipvs /lib/modules/$(uname -r)/modules.builtin # 2. 修改kube-proxy配置 kubectl edit configmap kube-proxy -n kube-system # mode: ipvs # 3. 重启kube-proxy kubectl delete pod -l k8s-app=kube-proxy -n kube-system📌 血泪教训:一次大促,Node节点突然NotReady。监控发现:Kubelet PLEG(Pod Lifecycle Event Generator)延迟>10s(正常<100ms)根因:某应用频繁创建/销毁临时容器(每秒20+)解决:临时:增加Kubelet资源限制--kube-reserved=cpu=500m,memory=1Gi长期:重构应用,避免高频创建Pod集群监控:给每个组件装上"心电图"核心监控指标清单(运维必备)组件关键指标告警阈值诊断命令API Serverrequest_duration_secondsP99> 1skubectl get --raw /metricsetcdwal_fsync_duration_seconds> 100msetcdctl endpoint statusSchedulerscheduling_duration_seconds> 10skubectl logs -l component=kube-schedulerKubeletpleg_relist_interval_seconds> 10sjournalctl -u kubeletNodememory.available< 10%kubectl describe node快速诊断脚本(保存为check-cluster.sh):#!/bin/bash echo "=== 集群健康检查报告 ($(date)) ===" # 1. 节点状态 echo -e "\n[1] 节点状态:" kubectl get nodes -o wide # 2. Pending的Pod echo -e "\n[2] Pending状态的Pod:" kubectl get pods --all-namespaces --field-selector=status.phase=Pending # 3. API Server延迟 echo -e "\n[3] API Server关键指标:" kubectl get --raw /metrics | grep -E "apiserver_request_duration_seconds|apiserver_current_inflight_requests" # 4. etcd健康状态 echo -e "\n[4] etcd健康检查 (需要在master节点执行):" if [ -x "$(command -v etcdctl)" ]; then ETCDCTL_API=3 etcdctl endpoint health --cluster fi echo -e "\n=== 诊断完成 ==="💡 专业建议:为每个组件设置黄金指标告警:• API Server: 5xx错误率 > 1%• etcd: 写入延迟 > 100ms• Scheduler: 调度队列深度 > 100这些告警比"节点宕机"提前30分钟发现问题!血泪教训:我们踩过的5个致命陷阱陷阱1:etcd版本与K8s不匹配• 现象:集群随机出现资源创建失败• 根因:K8s 1.22要求etcd 3.5+,但我们用了3.4• 解决:严格遵循版本兼容矩阵陷阱2:Controller Manager未配置leader选举• 现象:Controller Manager重启后,所有Deployment卡住• 解决:--leader-elect=true --leader-elect-lease-duration=15s 陷阱3:Kubelet证书未自动轮换• 现象:节点突然NotReady,日志报"x509证书过期"• 预防:--rotate-certificates=true --feature-gates=RotateKubeletServerCertificate=true 陷阱4:Scheduler资源不足• 现象:高负载时Pod调度延迟从1s飙升到60s+• 优化:resources: requests: cpu: 500m memory: 512Mi limits: cpu: 1 memory: 1Gi陷阱5:忽略组件间网络QoS• 现象:API Server与etcd通信偶尔超时• 解决:为关键组件配置网络优先级tc qdisc add dev eth0 root handle 1: htb tc class add dev eth0 parent 1: classid 1:1 htb rate 100mbit tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 2379 0xffff flowid 1:1从"救火队员"到"集群医生":我们的蜕变能力优化前优化后故障定位时间2-4小时5-15分钟集群稳定性每月3-5次严重故障连续180天无P0事故运维信心"重启试试""我知道问题在哪""以前看到Pending Pod就紧张,现在先看kubectl get events,基本5分钟定位问题。"行动指南:今晚就能做的3件事1. 今晚:在你的集群执行kubectl get --raw /metrics | grep apiserver_request_duration_seconds如果P99 > 500ms,说明API Server需要优化2. 明天:检查etcd磁盘IO性能iostat -dx 1 | grep etcd_device确保%util < 70%,await < 10ms3. 本周:为你的测试集群模拟一次etcd故障# 警告:仅在测试环境执行! systemctl stop etcd watch kubectl get nodes # 观察节点状态变化 systemctl start etcd # 恢复记住:真正的K8s高手,不是从不遇到问题,而是知道问题出在哪一层。从今天起,当集群异常时,先问自己:"这是API Server的问题?etcd的问题?控制器的问题?调度器的问题?还是节点的问题?" -
Linux性能分析神器sar介绍 sar介绍sar全称System Activity Reporter,翻译过来就是系统活动报告器。它属于sysstat工具包的一部分,可以收集、报告和保存系统活动信息。简单来说,sar就像是给服务器装了个黑匣子,24小时不间断地记录着系统的各种性能指标。CPU使用率、内存占用、磁盘IO、网络流量...这些数据它都会记录下来,等需要的时候随时可以调出来看。也就是说它不仅能实时监控,还能保存历史数据。比如查看昨天凌晨3点服务器在干什么?没问题,sar都有记录可以调取。sar相较于top、htop、iostat这些工具,top类工具适合实时查看当前状态,但不能保存历史数据。iostat专注于磁盘IO,功能比较单一。而sar是个综合性工具,既能实时监控,又能保存历史数据,还覆盖了系统的方方面面。日常工作中,通常是搭配使用发现问题时用top、htop快速查看当前状态用sar分析历史趋势,找出问题规律用专门的工具(如iotop、nethogs)深入分析具体问题sar不只是个监控工具,更是个分析工具。它记录的不仅是数字,更是系统运行的轨迹。学会读懂这些轨迹,你就能像福尔摩斯一样从蛛丝马迹中找出问题的真相。现在的系统越来越复杂,容器、微服务、云原生...新技术层出不穷。但无论技术怎么发展,底层的系统资源就那么几样:CPU、内存、磁盘、网络。掌握了sar,你就有了一把万能钥匙,能够打开性能问题的大门。安装配置大部分Linux发行版都预装了sysstat包,如果没有的话安装也很简单:#CentOS/RHEL系统 yum install sysstat # 或者新版本用dnf dnf install sysstat #Ubuntu/Debian系统: apt-get install sysstat #装完之后需要启动服务: systemctl enable sysstat systemctl start sysstat默认情况下,sar每10分钟收集一次数据,这个频率对大多数场景够用了。如果你想调整频率,可以编辑/etc/cron.d/sysstat文件。比如想改成每5分钟收集一次:*/5 * * * * root /usr/lib64/sa/sa1 1 1数据文件默认保存在/var/log/sa/目录下,文件名格式是saDD(DD是日期)。比如今天是15号,那数据就保存在sa15文件里。有个小坑要注意,sar的数据文件是二进制格式的,不能直接用cat或vi查看,必须通过sar命令来读取。sar常见使用场景CPU监控CPU监控,这是sar最基础也是最常用的功能。查看当前CPU使用情况:sar -u 1 5这条命令的意思是每1秒采样一次,总共采样5次。输出大概是这样的:03:25:01 PM CPU %user %nice %system %iowait %steal %idle 03:25:02 PM all 2.50 0.00 1.25 0.00 0.00 96.25 03:25:03 PM all 3.75 0.00 1.25 0.00 0.00 95.00每个字段的含义:%user: 用户态CPU使用率%nice: 运行在nice优先级下的用户态进程CPU使用率%system: 内核态CPU使用率%iowait: CPU等待IO操作的时间百分比%steal: 虚拟机环境下被其他虚拟机抢占的CPU时间%idle: CPU空闲时间百分比一般需要关注这几个指标:%user高说明应用程序在拼命干活,%system高可能是系统调用太多或者内核有瓶颈,%iowait高就要检查磁盘IO了。如果服务器是多核的,可以用-P参数查看每个CPU核心的情况:sar -u -P ALL 1 3这样就能看出负载是否均衡分布在各个核心上了。内存使用情况内存监控用-r参数:sar -r 1 5输出类似这样:03:30:01 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact 03:30:02 PM 1048576 3145728 75.00 102400 524288 2621440 62.50 1572864 786432关键指标解释:kbmemfree: 空闲内存(KB)kbmemused: 已使用内存(KB)%memused: 内存使用率kbbuffers: 内核缓冲区使用的内存kbcached: 缓存使用的内存kbcommit: 已提交的内存%commit: 提交内存占总内存的百分比这里有个常见误区,看到%memused很高就以为内存不够用了。其实Linux会把空闲内存用作缓存,真正需要关注的是当应用程序需要内存时,系统能否快速回收这些缓存。因此一般会结合swap使用情况一起看:sar -S 1 5如果swap使用率开始上升,那就真的需要考虑加内存了。还有个很有用的参数-B,可以查看内存分页情况:sar -B 1 5输出中的pgpgin/s和pgpgout/s分别表示每秒从磁盘读取和写入的页面数。如果这两个值很高,说明系统在频繁地进行内存和磁盘之间的数据交换。磁盘IO分析磁盘IO监控是性能分析的重头戏,用-d参数:sar -d 1 5输出会列出每个磁盘设备的IO统计信息:03:35:01 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 03:35:02 PM dev8-0 15.84 0.00 253.47 16.00 0.02 1.25 0.63 10.00重点关注这几个指标:tps: 每秒传输次数(IOPS)rd_sec/s: 每秒读取扇区数wr_sec/s: 每秒写入扇区数avgqu-sz: 平均队列长度await: 平均等待时间(毫秒)svctm: 平均服务时间(毫秒)%util: 磁盘利用率%util这个指标特别重要,如果接近100%说明磁盘已经满负荷了。但这里有个陷阱,对于SSD来说,%util达到100%不一定意味着性能瓶颈,因为SSD可以并行处理多个IO请求。await时间也很关键,如果这个值很高,用户就会感觉系统响应慢。我一般认为机械硬盘await超过20ms,SSD超过5ms就需要注意了。想看具体某个分区的IO情况,可以这样:sar -d -p 1 5-p参数会显示分区名而不是设备名,这样看起来更直观。网络流量监控网络监控用-n参数,这个参数后面可以跟不同的关键字:查看网络接口流量:sar -n DEV 1 5输出类似:03:40:01 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s 03:40:02 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 03:40:02 PM eth0 125.74 89.11 78.32 15.67 0.00 0.00 0.50rxpck/s, txpck/s: 每秒接收和发送的数据包数rxkB/s, txkB/s: 每秒接收和发送的KB数rxcmp/s, txcmp/s: 每秒接收和发送的压缩包数如果你想监控TCP连接状态:sar -n TCP 1 5这个命令会显示活跃连接数、新建连接数等信息,对于web服务器来说很有用。还有个很有意思的参数SOCK:sar -n SOCK 1 5可以看到系统中各种类型socket的数量,包括TCP、UDP、RAW等。有次我们的web服务突然变慢,用sar -n TCP一看,发现TIME_WAIT状态的连接数暴涨,原来是客户端没有正确复用连接导致的。查看历史数据sar最强大的地方就是能查看历史数据。默认情况下,当天的数据保存在/var/log/sa/saDD文件中。查看今天的CPU使用情况:sar -u查看昨天的:sar -u -f /var/log/sa/sa14 # 假设昨天是14号还可以指定时间范围:sar -u -s 08:00:00 -e 18:00:00这样就只看早上8点到晚上6点的数据了。这个功能经常用来分析问题的时间规律。比如用户反馈下午系统慢,就会看看下午时段的各项指标,往往能很快定位到问题。有个小技巧,如果你想生成一份漂亮的报告,可以把sar的输出重定向到文件:sar -A -f /var/log/sa/sa15 > system_report_15.txt-A参数表示输出所有统计信息,这样就得到了一份完整的系统性能报告。sar的进阶用法和小技巧除了基本的监控功能,sar还有一些很实用的进阶技巧。自定义输出格式 可以用-j参数将输出转换为JSON格式,方便程序处理:sar -u -j 1 3这个功能在写自动化脚本时特别有用。监控特定进程 虽然sar本身不能监控单个进程,但可以结合其他工具。比如先用ps找到进程PID,然后用pidstat(也是sysstat包的一部分):pidstat -p 1234 1 5数据文件管理 sar的数据文件会越来越大,需要定期清理。默认保存一个月,可以通过修改/etc/sysconfig/sysstat文件中的HISTORY参数来调整:HISTORY=7 # 只保存7天结合其他工具 sar输出的数据可以很方便地导入到Excel或者其他分析工具中。我经常把一周的数据导出来,用Excel做个图表,这样趋势就很明显了。还可以写个简单的脚本,定期提取关键指标并发送邮件报告:#!/bin/bash echo "昨日系统性能摘要:" > /tmp/daily_report.txt echo "CPU使用率:" >> /tmp/daily_report.txt sar -u -f /var/log/sa/sa$(date -d yesterday +%d) | tail -1 >> /tmp/daily_report.txt echo "内存使用率:" >> /tmp/daily_report.txt sar -r -f /var/log/sa/sa$(date -d yesterday +%d) | tail -1 >> /tmp/daily_report.txt mail -s "日报" admin@company.com < /tmp/daily_report.txt常见问题用sar这么多年,也踩过不少坑,总结几个常见问题:时区问题 sar显示的时间是系统本地时间,如果服务器时区设置不对,看历史数据时容易搞混。建议统一使用UTC时间。数据文件损坏 偶尔会遇到sa文件损坏的情况,这时sar会报错。通常是因为系统异常关机导致的。这种情况下只能删除损坏的文件,没有好的恢复方法。性能影响 虽然sar的开销很小,但在极高负载的系统上,频繁的数据收集还是可能产生影响。如果怀疑sar影响性能,可以临时停止sysstat服务测试一下。磁盘空间 长期运行后,/var/log/sa/目录会占用不少空间。记得定期检查并清理旧文件。实战案例案例1:神秘的CPU占用 有次用户投诉系统在特定时间变慢,但我们监控显示CPU使用率不高。后来用sar -u查看历史数据,发现问题时段%iowait很高,说明CPU在等待IO。接着用sar -d查看磁盘,发现某个磁盘的await时间异常,最终定位到是备份脚本在高峰期运行导致的IO冲突。案例2:内存泄漏追踪 应用程序运行一段时间后变慢,怀疑是内存泄漏。通过sar -r查看一周的内存使用趋势,发现kbmemused在持续增长,而且增长很规律。结合应用日志分析,找到了有问题的代码模块。案例3:网络瓶颈定位 网站访问慢,初步排查CPU和磁盘都正常。用sar -n DEV发现网卡的txpck/s(发包率)接近理论上限,原来是遭到了小包攻击。通过调整网卡参数和防火墙规则解决了问题。
-
AI优化指令:Lyra提示词 Reddit上有个提示词优化指令叫Lyra,最新优化版,最近在AI子里火得一塌糊涂,浏览量已经突破了600万,分享量也高达6万。Lyra提示词咋来的?Lyra提示词诞生于一个沮丧的Reddit用户在147次失败尝试后的灵光一现。这种元提示词技术颠覆了AI交互模式——不再猜测AI需要什么,而是让Lyra先采访你。Lyra独创的四步优化框架,模糊的想法里面清晰起来 :4D方法论体系:解构、诊断、开发、交付.使用方法: 先把Lyra完整提示词复制到DeepSeek. 然后按照自己实际的情况进行发问。 Lyra完整提示词(优化版)您好!我是Lyra,您的AI提示优化专家。我的使命是将任何用户输入转化为精准设计的提示,充分释放各平台AI的全部潜力。 4-D优化方法论 1. 解构分析 提取核心意图、关键要素和背景信息 确定输出要求和限制条件 梳理已有信息与缺失内容 2. 问题诊断 检查清晰度差距和模糊之处 验证具体性和完整性 评估结构和复杂性需求 3. 方案开发 根据请求类型选择最佳技术: 创意类 → 多视角分析 + 语气强调 技术类 → 基于约束 + 精准聚焦 教育类 → 示例演示 + 清晰结构 复杂类 → 思维链 + 系统框架 分配合适的AI角色/专业领域 增强背景信息并构建逻辑结构 4. 成果交付 构建优化后的提示 根据复杂度进行格式化 提供使用指导 优化技术 基础技巧: 角色分配、背景分层、输出规范、任务分解 高级技巧: 思维链、少量示例学习、多视角分析、约束优化 平台特性说明: ChatGPT/GPT-4: 结构化分段、对话启动器 Claude: 长上下文、推理框架 Gemini: 创意任务、对比分析 其他平台: 应用通用最佳实践 工作模式 详细模式: 使用智能默认值收集背景信息 提出2-3个针对性澄清问题 提供全面优化方案 基础模式: 快速修复主要问题 仅应用核心技巧 交付即用型提示 回复格式 简单请求: **优化后的提示:** [改进后的提示] **改进内容:** [主要优化点] 复杂请求: **优化后的提示:** [改进后的提示] **主要改进:** • [主要变更和优势] **应用技巧:** [简要说明] **使用建议:** [使用指导] 启动信息(必需) 激活时精确显示: “您好!我是Lyra,您的AI提示优化专家。我能将模糊的请求转化为精准有效的提示,从而获得更优质的结果。 我需要了解: 目标AI平台: ChatGPT、Claude、Gemini 或其他 优化模式: 详细模式(我将先询问关键问题)或基础模式(快速优化) 示例: “详细模式,用于ChatGPT — 帮我写一封营销邮件” “基础模式,用于Claude — 帮我完善简历” 您只需提供原始提示,剩下的优化工作交给我!” 处理流程 自动检测复杂度: 简单任务 → 基础模式 复杂/专业任务 → 详细模式 告知用户并提供覆盖选项 执行选定模式协议 交付优化后的提示 记忆注意: 不会保存优化会话中的任何信息。
-
Kafka集群优化指南 因Kafka具有吞吐量大,低延迟,高伸缩,高可靠性,高并发等特性,深受各大公司的喜爱,可以作为削峰填谷神器。但是Kafka“入门容易精通难”,它的很多默认配置,非常保守,像是给笔记本电脑用的,不是给服务器用的。因此,用好Kafka,可以从以下几个方面进行优化。关闭SwapJVM 最怕什么?最怕内存不够用,操作系统把它的内存页置换到 Swap 分区去。那一瞬间,GC 停顿时间(Stop The World)能长到让你怀疑人生。Kafka 是跑在 JVM 上的,一旦发生 Swap,Broker 就算没挂,延迟也得飙到好几秒。sysctl -w vm.swappiness=1别设成 0,设成 1,告诉内核,除非内存真的真的枯竭了,否则别动我的 Swap。最好直接在 /etc/fstab 里把 swap 这一行注释掉,永绝后患。设置文件句柄数(File Descriptors)Kafka 个狂暴的写手。它会打开无数个 Socket 连接,还会打开无数个日志分段文件(Segment Logs)。Linux 默认的 1024 个句柄,远远不够Kafka消耗的。修改 /etc/security/limits.conf,参照系统条件调整,例如下面的参数:soft nofile 100000 hard nofile 100000设置合理的存储位置Kafka 追求的是极致的顺序写盘速度。必须用物理盘! SSD 当然爽,但其实普通的 HDD 机械硬盘做 RAID 10 也完全够用,因为 Kafka 是顺序写,机械盘的顺序写性能并不差。但是不要把Kafka的数据目录挂载到网络存储NFS。也不要使用RAID 5级别的盘。RAID 5 的写性能惩罚太重了。不如直接用 JBOD(Just a Bunch of Disks),配置多个 log.dirs,让 Kafka 自己去把数据分摊到不同的盘上。这样坏一块盘,只丢一部分数据(靠副本恢复),总比 RAID 重建的时候整个阵列性能拖垮要强。合理配置ZooKeeper虽然现在的 Kafka 推出了 Kraft 模式(去 ZK 模式),但在生产环境,暂时还是使用 Zookeeper 保险一些。Kraft 虽好,但还得再跑个一两年才敢说是真的稳。ZK 集群搭建没啥好说的,节点数必须是奇数,3 个或者 5 个。为啥?为了防脑裂,过半数机制嘛。适当优化tickTime:默认是 2000ms。如果网络环境稍微抖一下,或者 GC 稍微卡一下,ZK 就会觉得节点挂了。稍微调大点,比如 3000ms 甚至 tickTime=2000 配合 initLimit 和 syncLimit 调大倍数,给网络抖动留点面子。ZK 的 dataLogDir 最好和 dataDir 分开,放在不同的磁盘上。ZK 对事务日志的写入延迟非常敏感,别让它跟快照文件抢磁盘 IO。优化server.properties配置 1. broker.id 这个不用说了吧,每个节点必须不一样。 2. listeners 和 advertised.listeners 这是新手最大的噩梦,没有之一。 多少人死在这上面,外网死活连不上,或者内网通了外网不通。listeners 是你耳朵听哪里的声音。比如 PLAINTEXT://0.0.0.0:9092,意思是只要是发到这台机器 9092 端口的,我都听。advertised.listeners 是你对外发出去的名片。告诉客户端:“嘿,你要找我,请打这个电话”。如果你在云服务器上,内网有个 IP 192.168.0.2,外网有个公网 IP 8.8.8.8。listeners 你就写内网 IP 或者 0.0.0.0。advertised.listeners 你必须写客户端能访问到的那个 IP。如果你的生产者在公网,这儿就得填 8.8.8.8。如果你填了内网 IP,客户端连上一看:“哦,去连 192.168.0.2”,然后它根本访问不到这个内网 IP,直接超时报错。 3. num.partitions 默认是 1。很多教程让你改大点,但是建议不要修改。这个是全局默认配置。你把它改成 100,以后随便建个测试 Topic 都是 100 个分区,成千上万个分区会把 ZK 和 Controller 累死的。保持默认 1 或者 3 就行了。真正重要的 Topic,建的时候手动指定分区数。 4. log.retention.hours 默认 168 小时(7天)。问问你们的存储预算。如果流量巨大,7天的数据能把你磁盘撑爆。我就见过因为日志没清掉,磁盘满了,Kafka 直接宕机的。对于很多日志类业务,保留 48 小时甚至 24 小时通常就够了。配合 log.retention.bytes 使用效果更佳,比如限制每个分区最大 1GB,双保险。 5. min.insync.replicas 这是数据安全的核心。默认是 1。这太危险了。如果是 1,只要 Leader 自己活着,它就敢告诉你“写入成功”。万一 Leader 下一秒挂了,副本还没同步过去,数据就丢了。建议设成 2。也就是说,至少得有两个节点(Leader + 一个 Follower)确认收到了消息,才算成功。当然,这得配合生产者的 acks=all 使用。如果你设了 min.insync.replicas=2,但是你的集群一共只有 2 个节点,那只要挂一台,你的集群就变成“只读”了,写入会全部失败。所以,3 节点集群是起步价。JVM相关设置Kafka 的设计理念非常特别。它极度依赖操作系统的 Page Cache(页缓存)。它读写文件,其实都是在跟操作系统的内存打交道,然后由操作系统异步刷到盘里。如果给 JVM 堆内存分了 30G,那留给操作系统的 Page Cache 就少了 30G。Kafka 反而会变慢。对于 Kafka Broker 来说,堆内存(Heap)通常 6G 到 10G 就绰绰有余了。它不需要在堆里缓存大量数据,它只是做个搬运工。剩下的几十 G 内存,全部留给操作系统去做 Page Cache,这才是性能起飞的秘密。修改启动脚本 kafka-server-start.sh,找到 KAFKA_HEAP_OPTS,改成:-Xmx6G -Xms6G记得加上 G1 垃圾回收器,JDK 1.8 以后 G1 的表现还是很稳的:-XX:+UseG1GC使用Systemd管理服务使用 nohup bin/kafka-server-start.sh config/server.properties &不方便不安全也不好管理,推荐使用Systemd进行统一管理。使用systemctl start kafka要安全规范许多。还能配置开机自启,进程挂了自动重启。vim /usr/lib/systemd/system/kafka.service[Unit] Description=Apache Kafka Requires=zookeeper.service After=zookeeper.service [Service] Type=simple User=kafka ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target查看日志验证服务状态用自带的 kafka-console-producer.sh 往里灌几条数据,再开个 kafka-console-consumer.sh 看看能不能读出来。还得看日志!去 logs/server.log 里看一眼。有没有 Error?有没有频繁的 GC 警告?有没有 Connection refused?如果有 Controller 频繁切换的日志,那说明你的网络或者 ZK 不稳,赶紧查,别等业务上线了再查。配置监控项Kafka 这东西,内部黑盒。你必须得配监控。最起码,得搞个 Kafka Eagle(现在叫 EFAK)或者 Prometheus + Grafana。你要盯着两个最重要的指标:Consumer Lag(消费积压):这是业务死活的晴雨表。Under Replicated Partitions(未同步分区):这个指标如果不为 0,说明有 Broker 掉队了或者挂了,数据处于危险状态,必须立刻马上处理。
-
批量服务器管理指南 管理好几十上百台服务器,核心思路是把 非标准化的烂摊子变成流水线作业。 凡是需要操作超过两次的,写成脚本。凡是需要在两台机器以上执行的,用 Ansible。凡是需要人肉盯着看的,交给 Prometheus。摸底与规范化处理刚接手大批量的机器时,最可怕的是乱。系统版本不一致,主机名未设置或与实际运行的服务不一致,等等。因此,为了方便维护大批量的服务器,第一步就是要规范主机名。规范主机名按照 地区-环境-业务-角色-序号 的方式来给每台服务器修改HostName。通过Shell脚本,配合IP和主机名对应表,循环跑一遍hostnamectl set-hostname命令。示例:bj-prod-shop-nginx-01bj:北京节点prod:生产环境shop:电商商城业务nginx:服务角色01:第一台统一系统版本要想批量维护服务器时不出错,操作系统版本必须锁死。别一会儿 CentOS 7.6,一会儿 7.9,一会儿又冒出个 Ubuntu。内核版本不同,有些内核参数的表现是不一样的。新机器到手,先跑一遍初始化脚本。主要包括以下内容:更换 YUM/APT 源: 换成阿里云或清华源,内网有条件的自建 Repo 更好,速度就是生命。安装基础工具包: vim, lrzsz, wget, curl, net-tools, sysstat (iostat, mpstat, sar 全靠它),tcpdump。哪怕现在用不上,装上总没错,省得排错时抓瞎。时间同步(Chrony) :把 NTP 换成 Chrony 吧,同步速度快,精度高。配置好内网的 NTP server,别让 100 台机器都去公网对时,防火墙要是严一点就瞎了。文件描述符限制: echo "* - nofile 65535" >> /etc/security/limits.conf。别等业务跑起来报 "Too many open files" 再去改,那时候通常得重启进程使用Ansible自动化执行命令大批量管理主机时,使用Ansible是最高效的选择。遇到在执行命令的时候遇到网络波动某些机器的某些命令没有执行,可以重复执行Ansilble脚本,因为它是幂等的。跑一次和跑十次,结果都是一样的,不会因为重复执行而出错。SSH优化Ansible 既然走 SSH,那 SSH 的连接速度就决定了你的执行效率。100 台机器,每台慢 1 秒,就是慢 100 秒。关闭 DNS 解析:在 /etc/ssh/sshd_config 里设置 UseDNS no。否则每次连上去它都要反查你的 IP,慢得要死。复用连接(ControlPersist):在你的管理机(Ansible控制端)的 ~/.ssh/config 或者 ansible.cfg 里配置开启 ControlMaster 和 ControlPersist。建立一次连接后,socket 文件保留一段时间,后续的命令直接复用通道,速度起飞。Ansible调优默认 Ansible 的并发数(forks)是 5。意思是一次只操作 5 台。遇到几百台机器的时候跑完得猴年马月。在 ansible.cfg 里,把 forks 改成 20 甚至 50。取决于你控制机的 CPU 和带宽。示例: 批量分发配置:修改所有 Nginx 的 nginx.conf。- name: Update Nginx Config hosts: web_group tasks: - name: Push config file copy: src: ./nginx.conf dest: /etc/nginx/nginx.conf backup: yes # 关键!覆盖前先备份,救命用的参数 notify: Reload Nginx # 触发器,只有文件变了才重启 handlers: - name: Reload Nginx service: name: nginx state: reloaded合理配置监控监控不是越多越好,是越准越好(可观测性)。没有监控,运维就是瞎子。但几十上百台机器,如果监控策略没搞好,会触发洪水泛滥一般的“告警风暴”。Prometheus + Grafana 是标配放弃 Zabbix 吧(虽然它是经典),Prometheus 在自动发现和容器化支持上更现代化。每台机器装个 node_exporter,这就把 CPU、内存、磁盘 IO、网络流量全收上来了。关于 Load Average 的误区很多新手喜欢监控 CPU 使用率,设定超过 80% 就报警。其实在 Linux 下,Load Average(负载) 往往比 CPU 使用率更能反映问题。CPU 高可能是单纯计算密集型任务,机器还能响应。但如果 Load 高(超过 CPU 核数),说明有进程在排队等待 CPU 或者等待磁盘 IO(D状态进程)。建议的报警策略:Load Average > CPU 核数 * 1.5(持续 5 分钟):严重报警。磁盘剩余空间 < 15%:预警(给人处理的时间)。磁盘 Inodes 使用率:别忘了这个!有时候磁盘没满,但小文件太多把 Inode 耗尽了,一样写不进数据。告警收敛这是个大坑。如果交换机抖了一下,大量机器同时报“网络不可达”,你的手机短信能瞬间炸了。因此需要配置 Alertmanager 的 group_wait 和 group_interval,把同一时间段、同一类别的报警合并成一条发出来。比如:“[严重] 100台机器 SSH 连接超时”,而不是 100 条短信。日志集中管理当日志存储在本地的时候,如果机器少,出问题了 ssh 上去 tail -f /var/log/messages还可以接受。但现在是个大的集群,里面可能有几十上百台机器。如果用户反馈“访问报错”,请求是随机分发到某台机器的,这时该怎么找?难道开 100 个终端窗口去 grep?Loki+Promtail+Grafana传统的 ELK (Elasticsearch, Logstash, Kibana) 确实强大,但是吃内存大户。Elasticsearch 维护起来也得要点水平。如果资源有限,推荐 Loki + Promtail + Grafana (PLG)方案。Promtail:部署在每台服务器上,极轻量,只负责采集日志文件,打上标签(Label),推送到 Loki。Loki:日志存储。它不像 ES 那样做全文索引(费内存),它只索引标签。查日志的时候类似 grep,但是是分布式的 grep。Grafana:展示界面。这样,开发跑过来问:“帮我查下这个订单号为什么失败”,你直接在 Grafana 里输入 {app="shop"} |= "ORDER123456",一秒钟出结果。安全防护Jumpserver 堡垒机千万别把服务器的真实 IP 和 root 密码直接给开发人员,甚至运维内部也别互相传私钥。搭建一个开源的 Jumpserver。统一入口:所有人都得先登堡垒机,再跳转。权限回收:某人离职了,你只需要在堡垒机上禁用他的账号,而不用去 100 台机器上删他的公钥。录像审计:这是甩锅神器。万一数据库被删了,回放录像,谁敲的 rm -rf,几点几分敲的,一清二楚。Sudo 权限控制别给所有人 root。用 Ansible 批量分发 /etc/sudoers 配置。利用 Linux 的 Group 功能,比如 dev 组只能 sudo systemctl restart nginx,而不能 sudo su -。精确控制权限范围。