搜索到
113
篇与
的结果
-
 grep/sed/awk实用案例 使用grep分析nginx日志# 统计访问最多的IP grep -oE "([0-9]{1,3}\.){3}[0-9]{1,3}" access.log | sort | uniq -c | sort -nr | head -10 # 查找可疑的爬虫请求 grep -i "bot\|spider\|crawler" access.log | grep -v "Googlebot" # 分析404错误的URL grep " 404 " access.log | awk '{print $7}' | sort | uniq -c | sort -nr # 查找大文件下载请求 grep -E " [0-9]{8,} " access.log | awk '$10 > 10000000 {print $1, $7, $10}' #查找当天出现错误码400和500开头最多的访客地址 grep "$(date '+%d/%b/%Y:%H')" access.log | grep -E " (4|5)[0-9]{2} " | wc -lsed配置文件批量修改# 修改nginx配置中的端口 sed -i 's/listen 80/listen 8080/g' /etc/nginx/sites-available/* # 批量替换数据库连接配置 sed -i 's/localhost:3306/db.example.com:3306/g' /var/www/*/config/*.php # 注释掉配置文件中的某些行 sed -i '/^debug/s/^/#/' /etc/myapp/config.ini # 去掉配置文件中的注释行和空行 sed -i '/^#/d; /^$/d' config.conf #批量修改100多个配置文件的数据库地址 find /var/www -name "database.php" -exec sed -i 's/old-db-server/new-db-server/g' {} \;awk分析nginx访问日志# 统计每个IP的访问次数 awk '{print $1}' access.log | sort | uniq -c | sort -nr | head -10 # 统计状态码分布 awk '{print $9}' access.log | sort | uniq -c | sort -nr # 计算平均响应大小 awk '{sum += $10; count++} END {print "Average size:", sum/count " bytes"}' access.log # 分析访问时间分布 awk '{print substr($4, 14, 2)}' access.log | sort | uniq -c | sort -nr # 找出响应时间最长的请求(需要nginx配置记录响应时间) awk '$NF > 1.0 {print $1, $7, $NF}' access.log | sort -k3 -nr | head -10awk分析系统日志# 统计不同级别的日志数量 awk '{print $5}' /var/log/messages | sort | uniq -c # 分析内存使用情况(从free命令输出) free -m | awk 'NR==2{printf "Memory Usage: %s/%sMB (%.2f%%)\n", $3,$2,$3*100/$2 }' # 分析磁盘使用情况 df -h | awk '$5 > 80 {print "Warning: " $1 " is " $5 " full"}'脚本:awk分析系统性能#!/bin/bash # 系统性能分析脚本 echo "=== CPU使用率 ===" top -bn1 | grep "Cpu(s)" | awk '{print "CPU使用率: " $2}' | sed 's/%us,//' #-b:表示批处理模式(batch mode)。在批处理模式下,top命令不会以交互式方式运行,而是直接将输出打印到标准输出(stdout)。这样便于将top的输出重定向到文件或通过管道传递给其他命令进行处理。 #-n:后面需要跟一个数字,表示top命令运行的迭代次数(iterations)。例如,-n1表示只运行一次迭代(即刷新一次)就退出。 echo "=== 内存使用情况 ===" free -m | awk 'NR==2{printf "内存使用: %s/%sMB (%.2f%%)\n", $3,$2,$3*100/$2}' echo "=== 磁盘使用情况 ===" df -h | awk '$5+0 > 80 {print "警告: " $1 " 使用率 " $5}' echo "=== 网络连接统计 ===" ss -tuln | awk ' BEGIN {tcp=0; udp=0} /^tcp/ {tcp++} /^udp/ {udp++} END {print "TCP连接: " tcp; print "UDP连接: " udp} ' echo "=== 最占CPU的进程 ===" ps aux | awk 'NR>1 {print $11, $3}' | sort -k2 -nr | head -5分析网站攻击# 找出可疑的攻击IP grep "$(date '+%d/%b/%Y')" access.log | \ grep -E " (4[0-9]{2}|5[0-9]{2}) " | \ awk '{print $1}' | \ sort | uniq -c | \ awk '$1 > 100 {print $2, $1}' | \ sort -k2 -nr #grep筛选今天的日志 #grep找出4xx和5xx错误 #awk提取IP地址 #sort和uniq统计每个IP的错误次数 #awk筛选错误超过100次的IP #sort按错误次数排序清理日志文件# 清理30天前的日志,只保留错误信息 find /var/log -name "*.log" -mtime +30 | while read file; do grep -E "(ERROR|FATAL|Exception)" "$file" | \ sed 's/^[0-9-]* [0-9:]*//' | \ awk '!seen[$0]++' > "${file}.clean" done生成监控报告#!/bin/bash # 生成每日访问报告 LOG_FILE="/var/log/nginx/access.log" REPORT_DATE=$(date '+%d/%b/%Y') echo "=== $REPORT_DATE 访问报告 ===" echo "总访问量:" grep "$REPORT_DATE" $LOG_FILE | wc -l echo "独立IP数:" grep "$REPORT_DATE" $LOG_FILE | awk '{print $1}' | sort -u | wc -l echo "状态码分布:" grep "$REPORT_DATE" $LOG_FILE | \ awk '{print $9}' | \ sort | uniq -c | \ sort -nr | \ sed 's/^[ ]*//' | \ awk '{printf "%-10s %s\n", $2, $1}' echo "热门页面TOP10:" grep "$REPORT_DATE" $LOG_FILE | \ grep " 200 " | \ awk '{print $7}' | \ sort | uniq -c | \ sort -nr | \ head -10 | \ sed 's/^[ ]*//' | \ awk '{printf "%-50s %s\n", $2, $1}'
grep/sed/awk实用案例 使用grep分析nginx日志# 统计访问最多的IP grep -oE "([0-9]{1,3}\.){3}[0-9]{1,3}" access.log | sort | uniq -c | sort -nr | head -10 # 查找可疑的爬虫请求 grep -i "bot\|spider\|crawler" access.log | grep -v "Googlebot" # 分析404错误的URL grep " 404 " access.log | awk '{print $7}' | sort | uniq -c | sort -nr # 查找大文件下载请求 grep -E " [0-9]{8,} " access.log | awk '$10 > 10000000 {print $1, $7, $10}' #查找当天出现错误码400和500开头最多的访客地址 grep "$(date '+%d/%b/%Y:%H')" access.log | grep -E " (4|5)[0-9]{2} " | wc -lsed配置文件批量修改# 修改nginx配置中的端口 sed -i 's/listen 80/listen 8080/g' /etc/nginx/sites-available/* # 批量替换数据库连接配置 sed -i 's/localhost:3306/db.example.com:3306/g' /var/www/*/config/*.php # 注释掉配置文件中的某些行 sed -i '/^debug/s/^/#/' /etc/myapp/config.ini # 去掉配置文件中的注释行和空行 sed -i '/^#/d; /^$/d' config.conf #批量修改100多个配置文件的数据库地址 find /var/www -name "database.php" -exec sed -i 's/old-db-server/new-db-server/g' {} \;awk分析nginx访问日志# 统计每个IP的访问次数 awk '{print $1}' access.log | sort | uniq -c | sort -nr | head -10 # 统计状态码分布 awk '{print $9}' access.log | sort | uniq -c | sort -nr # 计算平均响应大小 awk '{sum += $10; count++} END {print "Average size:", sum/count " bytes"}' access.log # 分析访问时间分布 awk '{print substr($4, 14, 2)}' access.log | sort | uniq -c | sort -nr # 找出响应时间最长的请求(需要nginx配置记录响应时间) awk '$NF > 1.0 {print $1, $7, $NF}' access.log | sort -k3 -nr | head -10awk分析系统日志# 统计不同级别的日志数量 awk '{print $5}' /var/log/messages | sort | uniq -c # 分析内存使用情况(从free命令输出) free -m | awk 'NR==2{printf "Memory Usage: %s/%sMB (%.2f%%)\n", $3,$2,$3*100/$2 }' # 分析磁盘使用情况 df -h | awk '$5 > 80 {print "Warning: " $1 " is " $5 " full"}'脚本:awk分析系统性能#!/bin/bash # 系统性能分析脚本 echo "=== CPU使用率 ===" top -bn1 | grep "Cpu(s)" | awk '{print "CPU使用率: " $2}' | sed 's/%us,//' #-b:表示批处理模式(batch mode)。在批处理模式下,top命令不会以交互式方式运行,而是直接将输出打印到标准输出(stdout)。这样便于将top的输出重定向到文件或通过管道传递给其他命令进行处理。 #-n:后面需要跟一个数字,表示top命令运行的迭代次数(iterations)。例如,-n1表示只运行一次迭代(即刷新一次)就退出。 echo "=== 内存使用情况 ===" free -m | awk 'NR==2{printf "内存使用: %s/%sMB (%.2f%%)\n", $3,$2,$3*100/$2}' echo "=== 磁盘使用情况 ===" df -h | awk '$5+0 > 80 {print "警告: " $1 " 使用率 " $5}' echo "=== 网络连接统计 ===" ss -tuln | awk ' BEGIN {tcp=0; udp=0} /^tcp/ {tcp++} /^udp/ {udp++} END {print "TCP连接: " tcp; print "UDP连接: " udp} ' echo "=== 最占CPU的进程 ===" ps aux | awk 'NR>1 {print $11, $3}' | sort -k2 -nr | head -5分析网站攻击# 找出可疑的攻击IP grep "$(date '+%d/%b/%Y')" access.log | \ grep -E " (4[0-9]{2}|5[0-9]{2}) " | \ awk '{print $1}' | \ sort | uniq -c | \ awk '$1 > 100 {print $2, $1}' | \ sort -k2 -nr #grep筛选今天的日志 #grep找出4xx和5xx错误 #awk提取IP地址 #sort和uniq统计每个IP的错误次数 #awk筛选错误超过100次的IP #sort按错误次数排序清理日志文件# 清理30天前的日志,只保留错误信息 find /var/log -name "*.log" -mtime +30 | while read file; do grep -E "(ERROR|FATAL|Exception)" "$file" | \ sed 's/^[0-9-]* [0-9:]*//' | \ awk '!seen[$0]++' > "${file}.clean" done生成监控报告#!/bin/bash # 生成每日访问报告 LOG_FILE="/var/log/nginx/access.log" REPORT_DATE=$(date '+%d/%b/%Y') echo "=== $REPORT_DATE 访问报告 ===" echo "总访问量:" grep "$REPORT_DATE" $LOG_FILE | wc -l echo "独立IP数:" grep "$REPORT_DATE" $LOG_FILE | awk '{print $1}' | sort -u | wc -l echo "状态码分布:" grep "$REPORT_DATE" $LOG_FILE | \ awk '{print $9}' | \ sort | uniq -c | \ sort -nr | \ sed 's/^[ ]*//' | \ awk '{printf "%-10s %s\n", $2, $1}' echo "热门页面TOP10:" grep "$REPORT_DATE" $LOG_FILE | \ grep " 200 " | \ awk '{print $7}' | \ sort | uniq -c | \ sort -nr | \ head -10 | \ sed 's/^[ ]*//' | \ awk '{printf "%-50s %s\n", $2, $1}' -
解决磁盘空间不足报错的常用方法 在收到磁盘空间不足的警报时,在不能对存储空间扩容的情况下,通常可以使用以下两种方式解决。方法一使用 df -h 命令查看磁盘空间的使用情况,确定哪个目录占用的磁盘空间过高;确定目录后,使用 du -h 命令进行逐级定位,找到占用空间最大的大文件;查看文件内容,确认是否需要保留。如果保留就压缩导出,不保留就直接删除。方法二使用find命令查找目录下的大文件,如大于500M的文件,然后根据实际情况判断是否需要删除或导出。注意:使用df -h命令有时并不能发现大文件,可能的原因是文件已被删除,但是进程仍然在调用这个文件。此时可以通过 lsof | grep delete 命令找到占用的进程,把这个进程kill掉然后重启服务即可。
-
zabbix实现自动修复 核心逻辑zabbix的“监控-触发-动作”联动机制核心原则只处理“原因明确、修复方式固定、重复执行无副作用”的问题,目的是减少人工的重复劳动,而非代替人工决策。适用场景服务/进程异常:服务意外停止(如nginx、mysql进程消失)→ 自动重启;进程资源占用过高(内存/cpu超限)→自动重启释放资源资源阈值超标:磁盘空间满(如日志占满)→ 自动清理旧文件\日志;非核心进程资源超限→自动杀死异常进程网络/端口问题:关键端口未监听(如80,3306)→ 自动重启对应服务;临时网络抖动导致断开→ 自动重连服务配置文件/权限异常:服务配置文件误改→ 自动覆盖为备份文件;目录/文件权限错误→ 自动修正权限不适用的场景复杂故障:数据损坏、硬件故障(如硬盘坏道);业务逻辑错误,代码bug需人工判断的情况:业务流量突增;多原因导致的同一现象高风险操作:删除数据库表、修改核心配置;可能引发连锁故障的操作
-
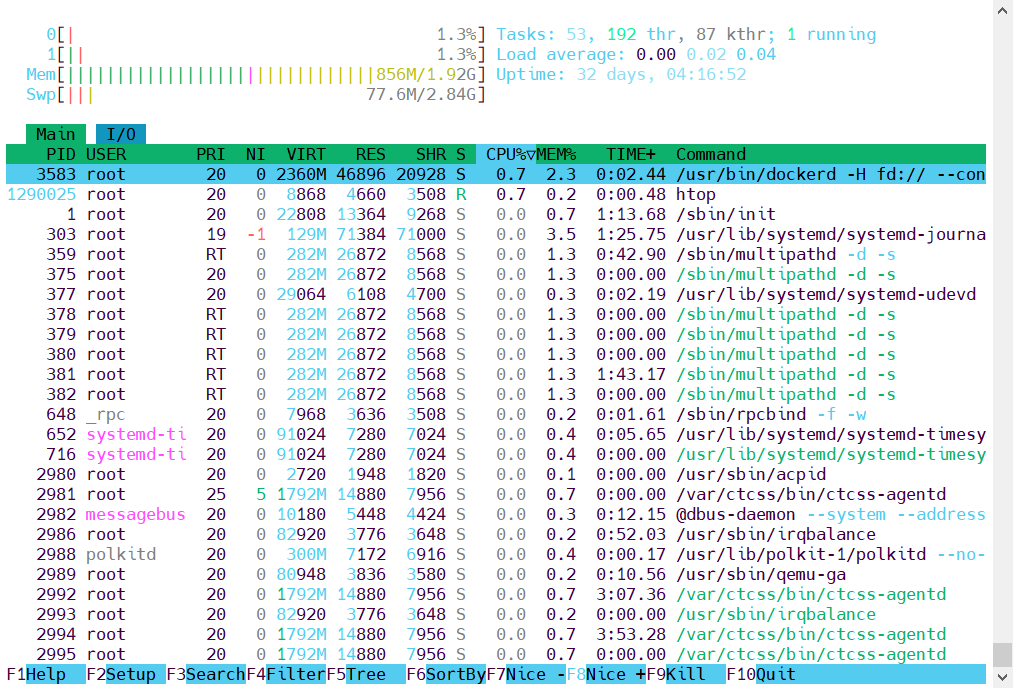
Linux常用系统监控工具介绍 在服务器管理和系统运维的日常工作中,实时监控系统资源使用情况是一项基础且关键的任务。除了比较基础的top命令外,比较常用的还有以下这些:htop:top命令的增强版glances:提供更全面的系统监控,包括网络、磁盘IO等atop:专注于长期性能监控和记录btop++:htop的现代替代品,提供更华丽的界面和更多功能iotop:专门监控磁盘IO使用情况nmon:IBM开发的系统监控工具,提供更多性能数据下面重点介绍一下htop命令。htop是一款功能强大且易于使用的Linux系统监控工具,它通过直观的界面和丰富的交互功能,大大提升了系统管理员监控和管理进程的效率。从基本的系统资源监控到复杂的进程管理,从简单的排序过滤到自定义显示配置,htop几乎能满足所有与进程监控相关的需求。在日常运维工作中,掌握htop的使用技巧不仅能帮助你快速定位系统问题,还能提高工作效率,减少排障时间。无论是处理高CPU负载、内存泄漏,还是需要快速终止失控进程,htop都能提供直观且高效的解决方案。htop界面详解运行htop时会看到一个分为上下两个部分的界面。顶部区域顶部区域显示系统的整体资源使用情况,包括:CPU使用率 每个CPU核心都有独立的使用率条,不同颜色代表不同类型的进程蓝色:低优先级进程绿色:普通用户进程红色:内核进程黄色/橙色:IRQ时间洋红色:软中断时间灰色:IO等待时间内存使用情况 显示物理内存和交换空间的使用百分比和具体数值绿色:已使用内存蓝色:缓冲区黄色/橙色:缓存负载平均值 显示1分钟、5分钟和15分钟的系统负载平均值正常运行时间 系统启动至今的运行时间任务统计 显示总进程数、运行中的进程数等信息底部区域底部区域显示系统中运行的进程列表,默认按CPU使用率排序。每个进程显示以下信息:PID:进程IDUSER:进程所有者PRI:进程优先级NI:nice值VIRT:虚拟内存大小RES:常驻内存大小SHR:共享内存大小S:进程状态(R=运行,S=睡眠,Z=僵尸等)CPU%:CPU使用百分比MEM%:内存使用百分比TIME+:进程运行时间Command:命令名称和参数htop操作技巧基本操作上下左右键:在进程列表中导航F5:切换树形视图,显示进程父子关系F6:选择排序字段F9:向进程发送信号(如终止进程)F10或q:退出htop进程管理htop最强大的功能之一是其直观的进程管理能力:终止进程:选中进程后按F9,然后选择要发送的信号(如SIGTERM或SIGKILL)调整进程优先级:选中进程后按F7(降低nice值)或F8(提高nice值)追踪进程系统调用:选中进程后按s,启动strace(需要安装strace工具)查看进程打开的文件:选中进程后按l,启动lsof(需要安装lsof工具)搜索功能在htop中,按下/键可以搜索特定进程。输入关键字后,htop会高亮显示匹配的进程。这在系统运行大量进程时特别有用。过滤功能 按下\键可以激活过滤功能,输入过滤条件后,htop只会显示符合条件的进程。例如,输入"apache"将只显示与apache相关的进程。自定义显示列 htop允许你自定义显示哪些进程信息列:按F2进入设置菜单选择"Columns"选项使用空格键选择或取消选择要显示的列F10保存并退出设置自定义配色方案如果你不喜欢默认的颜色方案,可以在设置菜单中进行更改:按F2进入设置菜单选择"Colors"选项选择预设的配色方案或自定义各元素的颜色F10保存并退出设置使用示例场景一:系统资源异常高,定位问题进程 当服务器CPU或内存使用率异常高时,可以通过以下步骤快速定位问题:启动htop,查看顶部的CPU和内存使用情况按F6,选择按CPU%或MEM%排序观察排在顶部的进程,这些通常是资源消耗最大的如果发现异常进程,可以进一步分析或终止它场景二:监控多核CPU的负载均衡情况在多核服务器上,理想情况下工作负载应该均匀分布在各个CPU核心上:启动htop,观察顶部的CPU使用率条检查各个核心的使用率是否平衡如果发现某个核心长期满负荷而其他核心空闲,可能表明应用程序不支持多线程或存在配置问题场景三:内存泄漏排查对于疑似内存泄漏的情况,可以使用htop进行初步排查:启动htop,按F6选择按MEM%排序记录可疑进程的内存使用情况定期观察这些进程的内存使用是否持续增长而不释放如果确认某进程存在内存泄漏,可以重启该进程作为临时解决方案,并进一步分析根本原因
-
PV与PVC之subPath(容器根目录设置) 在某些应用中,同一个Volume可能会被多个Pod或者一个Pod中的多个容器共享。此时可能存在个应用需要不同子目录的需求,可以通过Pod中volumeMounts定义的subPath字段进行设置。通过对subPath的设置,容器将以subPath设置的目录而不是Volume中提供的默认根目录作为根目录。subPath中的路径名称不能以“/”开头,需要使用相对路径的形式。如果希望通过环境变量的形式来设置subPath路径,可以通过subPathExpr字段来实现。subPath和subPathExpr字段是互斥的,不能同时使用。示例{tabs}{tabs-pane label="subPath"}--- apiVersion: v1 kind: Pod metadata: name: mysql spec: containers: - name: mysql image: mysql env: - name: MYSQL_ROOT_PASSWORD volue: "rootpassword" volumeMounts: - mountPath: /var/lib/mysql name: site-data subPath: mysql - name: php image: php volumeMounts: - mountPath: /var/www/html name: site-data subPath: html volumes: - name: site-data persitentVolumeClaim: claimName: site-data-pvc{/tabs-pane}{tabs-pane label="subPathExpr"}--- apiVersion: v1 kind: Pod metadata: name: pod1 spec: containers: - name: containers1 image: busybox command: ["sh","-c","sleep 6000"] env: - name: POD_NAME volueFrom: fieldRef: apiVersion: v1 FilePath: metadata.name volumeMounts: - name: workdir1 mountPath: /logs subPathExpr: $(POD_NAME) restartPolicy: Never volumes: - name: workdir1 hostpath: path: /var/log/pods {/tabs-pane}{/tabs}