搜索到
32
篇与
的结果
-
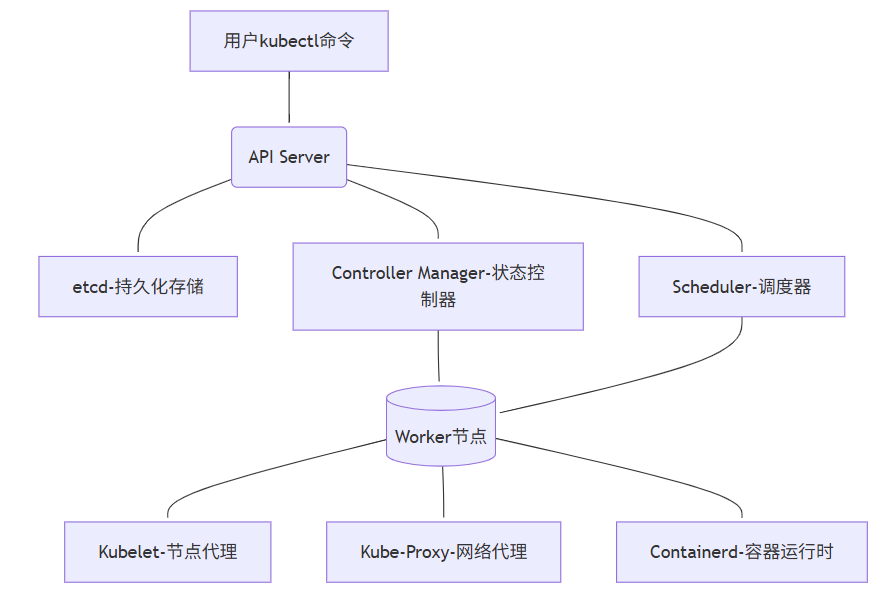
 K8s五大核心组件详解 居中 居右 颜色大小K8s不是"黑盒子" 一张图看懂核心架构先说个残酷真相:90%的K8s运维问题,根源在于不了解控制平面。就像修车只懂换轮胎,却不懂发动机原理。K8s架构全景图(简化实用版)💡 核心认知:K8s不是一组独立组件,而是一个精密协作的有机体。一个Pod的创建流程:用户指令 → API Server验证 → etcd持久化 → Controller创建资源 → Scheduler分配节点 → Kubelet启动容器五大核心组件:从"知道名字"到"摸透脾性"1. API Server:集群的"咽喉要道" 真实痛点:"为什么执行kubectl命令时卡住不动?为什么集群突然无法创建新资源?"工作原理(运维视角):• 所有操作的唯一入口(包括kubectl、控制器、调度器)• 不是简单的代理,而是认证/授权/准入控制的三重门神• 与etcd的交互是性能瓶颈关键关键参数(生产环境亲测):# kube-apiserver.yaml command: - kube-apiserver - --max-requests-inflight=1500 # 默认400,高负载集群必调 - --max-mutating-requests-inflight=500 # 写操作队列 - --etcd-servers=https://etcd1:2379,https://etcd2:2379 # etcd集群 - --request-timeout=1m # 防止客户端长时间占用故障排查锦囊:当API响应变慢时,先看这些指标:# 1. 查看API Server请求延迟 kubectl get --raw /metrics | grep apiserver_request_duration_seconds_bucket # 2. 检查活跃连接数 netstat -ant | grep ':6443' | wc -l # 6443是API Server端口 # 3. 紧急情况:重启API Server(需谨慎) systemctl restart kube-apiserver📌 血泪教训:曾因某次发布,一个错误的CRD定义导致API Server CPU 100%。根源:CRD验证逻辑过于复杂,每个请求都执行全量校验。解决:使用--runtime-config=api/all=false临时禁用问题API组。2. etcd:集群的"心脏起搏器" 真实痛点:"集群操作突然变卡,但节点和Pod看起来正常""etcd数据目录突然暴涨,磁盘空间告急"工作原理(运维视角):• 不只是KV存储,更是整个集群状态的唯一真相源• 使用Raft协议保证数据一致性(奇数节点,3/5/7)• 写操作必须经过Leader,读操作可从Follower获取etcd性能调优关键:# 1. 必须使用SSD磁盘!机械盘是性能杀手 mount -t xfs -o noatime,nodiratime,logbsize=256k /dev/sdb1 /var/lib/etcd # 2. 定期碎片整理(每月一次) etcdctl defrag --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key # 3. 关键监控指标 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.01"} # 99%请求应在10ms内完成 etcd_mvcc_db_total_size_in_bytes # 数据库大小灾难恢复实战:# 1. 备份(每天凌晨执行) ETCDCTL_API=3 etcdctl --endpoints=$ENDPOINTS snapshot save snapshot.db # 2. 恢复(灾难场景) ETCDCTL_API=3 etcdctl snapshot restore snapshot.db \ --name etcd1 \ --initial-cluster "etcd1=http://10.0.0.1:2380,etcd2=http://10.0.0.2:2380" \ --initial-cluster-token my-etcd-token \ --initial-advertise-peer-urls http://10.0.0.1:2380 # 3. 重启etcd服务 systemctl restart etcd 💡 我们的真实案例:一次大促前,etcd磁盘IO延迟从2ms飙升到200ms。排查过程:1.iostat -dx 1 发现%util=100%2.etcd_disk_backend_commit_duration_seconds 指标异常3.分析发现某团队在频繁更新ConfigMap(每秒50次)解决:限制客户端QPS + 合并ConfigMap更新3. Controller Manager:集群的"自动驾驶仪" 真实痛点:"Deployment配置了3副本,但只运行了2个Pod""节点宕机后,Pod没有自动迁移到其他节点"核心机制(运维视角):• 不是单个组件,而是多个控制器的集合(Deployment、Node、Endpoint等)• 工作模式:Informer Loop(List-Watch-Process)• 每个控制器独立工作,但共享API Server连接关键控制器职责:控制器职责常见问题Deployment Controller管理ReplicaSet和Pod无法扩缩容Node Controller监控节点状态,标记NotReady节点状态异常Endpoint Controller同步Service和Pod端点Service无法访问PodNamespace Controller清理已删除命名空间的资源命名空间卡在Terminating性能优化实战:# kube-controller-manager.yaml command: - kube-controller-manager - --concurrent-deployment-syncs=20 # 默认5,并行处理Deployment - --node-monitor-grace-period=40s # 节点失联容忍时间 - --pod-eviction-timeout=5m0s # 节点NotReady后驱逐Pod等待时间故障排查命令:# 1. 查看控制器工作队列 kubectl get --raw /metrics | grep workqueue_queue_duration_seconds # 2. 诊断Node Controller问题 kubectl get events --sort-by=.metadata.creationTimestamp | grep -i node # 3. 强制同步资源(紧急恢复) # 注意:需在master节点执行 curl -k -v -XPATCH \ -H "Accept: application/json, */*" \ -H "Content-Type: application/strategic-merge-patch+json" \ -H "Authorization: Bearer $(cat /var/run/secrets/kubernetes.io/serviceaccount/token)" \ https://kubernetes.default.svc/api/v1/namespaces/default/deployments/my-app/status \ --data '{"status":{"observedGeneration":0}}'📌 踩坑实录:一次版本升级后,所有Deployment无法扩缩容。现象:kubectl describe deployment显示"Progressing"但无变化真相:Controller Manager与API Server版本不兼容教训:永远先升级控制平面,再升级节点;永远不要跳过次要版本4. Scheduler:集群的"资源分配大师" 真实痛点:"新Pod一直卡在Pending状态""节点资源明明充足,但Scheduler不调度"调度过程揭秘(运维视角):1. 过滤阶段(Filtering):排除不满足条件的节点(资源不足、污点不匹配等)2. 打分阶段(Scoring):为剩余节点打分(资源均衡、亲和性等)3. 绑定阶段(Binding):选择最高分节点,通知API Server调度器性能调优:# kube-scheduler.yaml apiVersion: kubescheduler.config.k8s.io/v1beta3 kind: KubeSchedulerConfiguration profiles: - schedulerName: default-scheduler plugins: score: disabled: - name: NodeResourcesLeastAllocated # 禁用低效插件 enabled: - name: NodeResourcesBalancedAllocation weight: 2 filter: enabled: - name: PodTopologySpread诊断Pending Pod的终极命令:# 1. 查看调度失败原因 kubectl get events --field-selector involvedObject.name=my-pod -n my-namespace # 2. 详细诊断(关键!) kubectl describe pod my-pod | grep -A 10 "Events:" # 3. 模拟调度过程 kubectl get --raw "/apis/scheduling.k8s.io/v1/priorityclasses"💡 实战案例:我们曾遇到Pod卡在Pending,但节点资源充足。排查:• kubectl describe pod显示"Tolerates: node.kubernetes.io/not-ready:NoExecute"• 发现节点有临时污点解决:tolerations: - key: "node.kubernetes.io/not-ready" operator: "Exists" effect: "NoExecute" tolerationSeconds: 300 # 等待300秒后驱逐5. 工作节点组件:集群的"一线工人" 三剑客职责:• Kubelet:节点的"管家",管理Pod生命周期• Kube-Proxy:节点的"交通警察",维护Service网络规则• Containerd:节点的"发动机",运行容器Kubelet关键优化:# /var/lib/kubelet/config.yaml apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration maxPods: 110 # 默认110,根据节点规格调整 imageGCHighThresholdPercent: 85 # 磁盘使用超过85%清理镜像 imageGCLowThresholdPercent: 80 serializeImagePulls: false # 并行拉取镜像Kube-Proxy模式选择:模式优点缺点适用场景iptables稳定,兼容性好规则复杂时性能下降小规模集群(<100节点)ipvs高性能,连接复用需要内核支持大规模集群(>100节点)切换到ipvs模式:# 1. 检查内核支持 grep -e ipvs /lib/modules/$(uname -r)/modules.builtin # 2. 修改kube-proxy配置 kubectl edit configmap kube-proxy -n kube-system # mode: ipvs # 3. 重启kube-proxy kubectl delete pod -l k8s-app=kube-proxy -n kube-system📌 血泪教训:一次大促,Node节点突然NotReady。监控发现:Kubelet PLEG(Pod Lifecycle Event Generator)延迟>10s(正常<100ms)根因:某应用频繁创建/销毁临时容器(每秒20+)解决:临时:增加Kubelet资源限制--kube-reserved=cpu=500m,memory=1Gi长期:重构应用,避免高频创建Pod集群监控:给每个组件装上"心电图"核心监控指标清单(运维必备)组件关键指标告警阈值诊断命令API Serverrequest_duration_secondsP99> 1skubectl get --raw /metricsetcdwal_fsync_duration_seconds> 100msetcdctl endpoint statusSchedulerscheduling_duration_seconds> 10skubectl logs -l component=kube-schedulerKubeletpleg_relist_interval_seconds> 10sjournalctl -u kubeletNodememory.available< 10%kubectl describe node快速诊断脚本(保存为check-cluster.sh):#!/bin/bash echo "=== 集群健康检查报告 ($(date)) ===" # 1. 节点状态 echo -e "\n[1] 节点状态:" kubectl get nodes -o wide # 2. Pending的Pod echo -e "\n[2] Pending状态的Pod:" kubectl get pods --all-namespaces --field-selector=status.phase=Pending # 3. API Server延迟 echo -e "\n[3] API Server关键指标:" kubectl get --raw /metrics | grep -E "apiserver_request_duration_seconds|apiserver_current_inflight_requests" # 4. etcd健康状态 echo -e "\n[4] etcd健康检查 (需要在master节点执行):" if [ -x "$(command -v etcdctl)" ]; then ETCDCTL_API=3 etcdctl endpoint health --cluster fi echo -e "\n=== 诊断完成 ==="💡 专业建议:为每个组件设置黄金指标告警:• API Server: 5xx错误率 > 1%• etcd: 写入延迟 > 100ms• Scheduler: 调度队列深度 > 100这些告警比"节点宕机"提前30分钟发现问题!血泪教训:我们踩过的5个致命陷阱陷阱1:etcd版本与K8s不匹配• 现象:集群随机出现资源创建失败• 根因:K8s 1.22要求etcd 3.5+,但我们用了3.4• 解决:严格遵循版本兼容矩阵陷阱2:Controller Manager未配置leader选举• 现象:Controller Manager重启后,所有Deployment卡住• 解决:--leader-elect=true --leader-elect-lease-duration=15s 陷阱3:Kubelet证书未自动轮换• 现象:节点突然NotReady,日志报"x509证书过期"• 预防:--rotate-certificates=true --feature-gates=RotateKubeletServerCertificate=true 陷阱4:Scheduler资源不足• 现象:高负载时Pod调度延迟从1s飙升到60s+• 优化:resources: requests: cpu: 500m memory: 512Mi limits: cpu: 1 memory: 1Gi陷阱5:忽略组件间网络QoS• 现象:API Server与etcd通信偶尔超时• 解决:为关键组件配置网络优先级tc qdisc add dev eth0 root handle 1: htb tc class add dev eth0 parent 1: classid 1:1 htb rate 100mbit tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 2379 0xffff flowid 1:1从"救火队员"到"集群医生":我们的蜕变能力优化前优化后故障定位时间2-4小时5-15分钟集群稳定性每月3-5次严重故障连续180天无P0事故运维信心"重启试试""我知道问题在哪""以前看到Pending Pod就紧张,现在先看kubectl get events,基本5分钟定位问题。"行动指南:今晚就能做的3件事1. 今晚:在你的集群执行kubectl get --raw /metrics | grep apiserver_request_duration_seconds如果P99 > 500ms,说明API Server需要优化2. 明天:检查etcd磁盘IO性能iostat -dx 1 | grep etcd_device确保%util < 70%,await < 10ms3. 本周:为你的测试集群模拟一次etcd故障# 警告:仅在测试环境执行! systemctl stop etcd watch kubectl get nodes # 观察节点状态变化 systemctl start etcd # 恢复记住:真正的K8s高手,不是从不遇到问题,而是知道问题出在哪一层。从今天起,当集群异常时,先问自己:"这是API Server的问题?etcd的问题?控制器的问题?调度器的问题?还是节点的问题?"
K8s五大核心组件详解 居中 居右 颜色大小K8s不是"黑盒子" 一张图看懂核心架构先说个残酷真相:90%的K8s运维问题,根源在于不了解控制平面。就像修车只懂换轮胎,却不懂发动机原理。K8s架构全景图(简化实用版)💡 核心认知:K8s不是一组独立组件,而是一个精密协作的有机体。一个Pod的创建流程:用户指令 → API Server验证 → etcd持久化 → Controller创建资源 → Scheduler分配节点 → Kubelet启动容器五大核心组件:从"知道名字"到"摸透脾性"1. API Server:集群的"咽喉要道" 真实痛点:"为什么执行kubectl命令时卡住不动?为什么集群突然无法创建新资源?"工作原理(运维视角):• 所有操作的唯一入口(包括kubectl、控制器、调度器)• 不是简单的代理,而是认证/授权/准入控制的三重门神• 与etcd的交互是性能瓶颈关键关键参数(生产环境亲测):# kube-apiserver.yaml command: - kube-apiserver - --max-requests-inflight=1500 # 默认400,高负载集群必调 - --max-mutating-requests-inflight=500 # 写操作队列 - --etcd-servers=https://etcd1:2379,https://etcd2:2379 # etcd集群 - --request-timeout=1m # 防止客户端长时间占用故障排查锦囊:当API响应变慢时,先看这些指标:# 1. 查看API Server请求延迟 kubectl get --raw /metrics | grep apiserver_request_duration_seconds_bucket # 2. 检查活跃连接数 netstat -ant | grep ':6443' | wc -l # 6443是API Server端口 # 3. 紧急情况:重启API Server(需谨慎) systemctl restart kube-apiserver📌 血泪教训:曾因某次发布,一个错误的CRD定义导致API Server CPU 100%。根源:CRD验证逻辑过于复杂,每个请求都执行全量校验。解决:使用--runtime-config=api/all=false临时禁用问题API组。2. etcd:集群的"心脏起搏器" 真实痛点:"集群操作突然变卡,但节点和Pod看起来正常""etcd数据目录突然暴涨,磁盘空间告急"工作原理(运维视角):• 不只是KV存储,更是整个集群状态的唯一真相源• 使用Raft协议保证数据一致性(奇数节点,3/5/7)• 写操作必须经过Leader,读操作可从Follower获取etcd性能调优关键:# 1. 必须使用SSD磁盘!机械盘是性能杀手 mount -t xfs -o noatime,nodiratime,logbsize=256k /dev/sdb1 /var/lib/etcd # 2. 定期碎片整理(每月一次) etcdctl defrag --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key # 3. 关键监控指标 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.01"} # 99%请求应在10ms内完成 etcd_mvcc_db_total_size_in_bytes # 数据库大小灾难恢复实战:# 1. 备份(每天凌晨执行) ETCDCTL_API=3 etcdctl --endpoints=$ENDPOINTS snapshot save snapshot.db # 2. 恢复(灾难场景) ETCDCTL_API=3 etcdctl snapshot restore snapshot.db \ --name etcd1 \ --initial-cluster "etcd1=http://10.0.0.1:2380,etcd2=http://10.0.0.2:2380" \ --initial-cluster-token my-etcd-token \ --initial-advertise-peer-urls http://10.0.0.1:2380 # 3. 重启etcd服务 systemctl restart etcd 💡 我们的真实案例:一次大促前,etcd磁盘IO延迟从2ms飙升到200ms。排查过程:1.iostat -dx 1 发现%util=100%2.etcd_disk_backend_commit_duration_seconds 指标异常3.分析发现某团队在频繁更新ConfigMap(每秒50次)解决:限制客户端QPS + 合并ConfigMap更新3. Controller Manager:集群的"自动驾驶仪" 真实痛点:"Deployment配置了3副本,但只运行了2个Pod""节点宕机后,Pod没有自动迁移到其他节点"核心机制(运维视角):• 不是单个组件,而是多个控制器的集合(Deployment、Node、Endpoint等)• 工作模式:Informer Loop(List-Watch-Process)• 每个控制器独立工作,但共享API Server连接关键控制器职责:控制器职责常见问题Deployment Controller管理ReplicaSet和Pod无法扩缩容Node Controller监控节点状态,标记NotReady节点状态异常Endpoint Controller同步Service和Pod端点Service无法访问PodNamespace Controller清理已删除命名空间的资源命名空间卡在Terminating性能优化实战:# kube-controller-manager.yaml command: - kube-controller-manager - --concurrent-deployment-syncs=20 # 默认5,并行处理Deployment - --node-monitor-grace-period=40s # 节点失联容忍时间 - --pod-eviction-timeout=5m0s # 节点NotReady后驱逐Pod等待时间故障排查命令:# 1. 查看控制器工作队列 kubectl get --raw /metrics | grep workqueue_queue_duration_seconds # 2. 诊断Node Controller问题 kubectl get events --sort-by=.metadata.creationTimestamp | grep -i node # 3. 强制同步资源(紧急恢复) # 注意:需在master节点执行 curl -k -v -XPATCH \ -H "Accept: application/json, */*" \ -H "Content-Type: application/strategic-merge-patch+json" \ -H "Authorization: Bearer $(cat /var/run/secrets/kubernetes.io/serviceaccount/token)" \ https://kubernetes.default.svc/api/v1/namespaces/default/deployments/my-app/status \ --data '{"status":{"observedGeneration":0}}'📌 踩坑实录:一次版本升级后,所有Deployment无法扩缩容。现象:kubectl describe deployment显示"Progressing"但无变化真相:Controller Manager与API Server版本不兼容教训:永远先升级控制平面,再升级节点;永远不要跳过次要版本4. Scheduler:集群的"资源分配大师" 真实痛点:"新Pod一直卡在Pending状态""节点资源明明充足,但Scheduler不调度"调度过程揭秘(运维视角):1. 过滤阶段(Filtering):排除不满足条件的节点(资源不足、污点不匹配等)2. 打分阶段(Scoring):为剩余节点打分(资源均衡、亲和性等)3. 绑定阶段(Binding):选择最高分节点,通知API Server调度器性能调优:# kube-scheduler.yaml apiVersion: kubescheduler.config.k8s.io/v1beta3 kind: KubeSchedulerConfiguration profiles: - schedulerName: default-scheduler plugins: score: disabled: - name: NodeResourcesLeastAllocated # 禁用低效插件 enabled: - name: NodeResourcesBalancedAllocation weight: 2 filter: enabled: - name: PodTopologySpread诊断Pending Pod的终极命令:# 1. 查看调度失败原因 kubectl get events --field-selector involvedObject.name=my-pod -n my-namespace # 2. 详细诊断(关键!) kubectl describe pod my-pod | grep -A 10 "Events:" # 3. 模拟调度过程 kubectl get --raw "/apis/scheduling.k8s.io/v1/priorityclasses"💡 实战案例:我们曾遇到Pod卡在Pending,但节点资源充足。排查:• kubectl describe pod显示"Tolerates: node.kubernetes.io/not-ready:NoExecute"• 发现节点有临时污点解决:tolerations: - key: "node.kubernetes.io/not-ready" operator: "Exists" effect: "NoExecute" tolerationSeconds: 300 # 等待300秒后驱逐5. 工作节点组件:集群的"一线工人" 三剑客职责:• Kubelet:节点的"管家",管理Pod生命周期• Kube-Proxy:节点的"交通警察",维护Service网络规则• Containerd:节点的"发动机",运行容器Kubelet关键优化:# /var/lib/kubelet/config.yaml apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration maxPods: 110 # 默认110,根据节点规格调整 imageGCHighThresholdPercent: 85 # 磁盘使用超过85%清理镜像 imageGCLowThresholdPercent: 80 serializeImagePulls: false # 并行拉取镜像Kube-Proxy模式选择:模式优点缺点适用场景iptables稳定,兼容性好规则复杂时性能下降小规模集群(<100节点)ipvs高性能,连接复用需要内核支持大规模集群(>100节点)切换到ipvs模式:# 1. 检查内核支持 grep -e ipvs /lib/modules/$(uname -r)/modules.builtin # 2. 修改kube-proxy配置 kubectl edit configmap kube-proxy -n kube-system # mode: ipvs # 3. 重启kube-proxy kubectl delete pod -l k8s-app=kube-proxy -n kube-system📌 血泪教训:一次大促,Node节点突然NotReady。监控发现:Kubelet PLEG(Pod Lifecycle Event Generator)延迟>10s(正常<100ms)根因:某应用频繁创建/销毁临时容器(每秒20+)解决:临时:增加Kubelet资源限制--kube-reserved=cpu=500m,memory=1Gi长期:重构应用,避免高频创建Pod集群监控:给每个组件装上"心电图"核心监控指标清单(运维必备)组件关键指标告警阈值诊断命令API Serverrequest_duration_secondsP99> 1skubectl get --raw /metricsetcdwal_fsync_duration_seconds> 100msetcdctl endpoint statusSchedulerscheduling_duration_seconds> 10skubectl logs -l component=kube-schedulerKubeletpleg_relist_interval_seconds> 10sjournalctl -u kubeletNodememory.available< 10%kubectl describe node快速诊断脚本(保存为check-cluster.sh):#!/bin/bash echo "=== 集群健康检查报告 ($(date)) ===" # 1. 节点状态 echo -e "\n[1] 节点状态:" kubectl get nodes -o wide # 2. Pending的Pod echo -e "\n[2] Pending状态的Pod:" kubectl get pods --all-namespaces --field-selector=status.phase=Pending # 3. API Server延迟 echo -e "\n[3] API Server关键指标:" kubectl get --raw /metrics | grep -E "apiserver_request_duration_seconds|apiserver_current_inflight_requests" # 4. etcd健康状态 echo -e "\n[4] etcd健康检查 (需要在master节点执行):" if [ -x "$(command -v etcdctl)" ]; then ETCDCTL_API=3 etcdctl endpoint health --cluster fi echo -e "\n=== 诊断完成 ==="💡 专业建议:为每个组件设置黄金指标告警:• API Server: 5xx错误率 > 1%• etcd: 写入延迟 > 100ms• Scheduler: 调度队列深度 > 100这些告警比"节点宕机"提前30分钟发现问题!血泪教训:我们踩过的5个致命陷阱陷阱1:etcd版本与K8s不匹配• 现象:集群随机出现资源创建失败• 根因:K8s 1.22要求etcd 3.5+,但我们用了3.4• 解决:严格遵循版本兼容矩阵陷阱2:Controller Manager未配置leader选举• 现象:Controller Manager重启后,所有Deployment卡住• 解决:--leader-elect=true --leader-elect-lease-duration=15s 陷阱3:Kubelet证书未自动轮换• 现象:节点突然NotReady,日志报"x509证书过期"• 预防:--rotate-certificates=true --feature-gates=RotateKubeletServerCertificate=true 陷阱4:Scheduler资源不足• 现象:高负载时Pod调度延迟从1s飙升到60s+• 优化:resources: requests: cpu: 500m memory: 512Mi limits: cpu: 1 memory: 1Gi陷阱5:忽略组件间网络QoS• 现象:API Server与etcd通信偶尔超时• 解决:为关键组件配置网络优先级tc qdisc add dev eth0 root handle 1: htb tc class add dev eth0 parent 1: classid 1:1 htb rate 100mbit tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 2379 0xffff flowid 1:1从"救火队员"到"集群医生":我们的蜕变能力优化前优化后故障定位时间2-4小时5-15分钟集群稳定性每月3-5次严重故障连续180天无P0事故运维信心"重启试试""我知道问题在哪""以前看到Pending Pod就紧张,现在先看kubectl get events,基本5分钟定位问题。"行动指南:今晚就能做的3件事1. 今晚:在你的集群执行kubectl get --raw /metrics | grep apiserver_request_duration_seconds如果P99 > 500ms,说明API Server需要优化2. 明天:检查etcd磁盘IO性能iostat -dx 1 | grep etcd_device确保%util < 70%,await < 10ms3. 本周:为你的测试集群模拟一次etcd故障# 警告:仅在测试环境执行! systemctl stop etcd watch kubectl get nodes # 观察节点状态变化 systemctl start etcd # 恢复记住:真正的K8s高手,不是从不遇到问题,而是知道问题出在哪一层。从今天起,当集群异常时,先问自己:"这是API Server的问题?etcd的问题?控制器的问题?调度器的问题?还是节点的问题?" -
容器间通信延迟高的排查流程 故障现象单个服务很快,但组合起来速度就慢。具体表现:{callout color="#EACDD1"}页面加载从2秒延迟到5秒接口响应延迟明显偶尔出现超时错误数据库查询正常应用资源正常(CPU、内存等)带宽充足{/callout}问题定位1.抓包分析进入api网关容器(本例中使用nginx容器作为入口网关),对相应端口的数据进行抓包分析。 # 抓包命令 docker exec nginx tcpdump -i eth0 -nn -tttt 'tcp port 8080' -w /tmp/capture.pcap #tcpdump: 使用网络抓包工具 tcpdump #-i eth0: 指定监听的网络接口为 eth0 #-nn: 不解析主机名和端口号(直接显示IP和数字端口) #-tttt: 使用完整格式的时间戳(年月日时分秒) #'tcp port 8080': 过滤条件,只捕获 TCP 协议且目标或源端口为 8080 的流量 #-w /tmp/capture.pcap: 将捕获的数据包写入到容器内的 /tmp/capture.pcap 文件,而不是显示在终端 # Wireshark分析结果 时间线: 00:00.000 请求到达nginx 00:12.000 nginx → service-a (12ms延迟) 00:18.000 service-a收到 (6ms) 00:25.000 service-a → service-b (7ms) 00:45.000 service-b收到 (20ms !!!) 00:78.000 service-b处理完成 (33ms) 00:98.000 service-a收到响应 (20ms !!!) 00:105.000 nginx收到 (7ms) 00:130.000 返回给用户 (25ms) 总计:130ms 2.发现问题容器间通信延迟异常高,尤其是 service-a 和 service-b 之间。3.分析问题为什么容器间通信会有20ms延迟?{callout color="#EACDD1"}正常情况:同一主机的容器通信应该<1ms我们的却有20-30ms原因:Docker默认使用Bridge网络模式数据要经过:容器 → veth → bridge → NAT → veth → 容器每一层都有损耗网络路径:容器A → veth0 → docker0网桥 → iptables规则(300+条) → NAT转换 → veth1 → 容器B 损耗来源:veth虚拟网卡:3-5ms网桥转发:2-3msiptables遍历:5-8msNAT转换:1-2msconntrack查表:1-2ms总损耗:12-20ms{/callout}docker网络模式对比1.bridge模式(默认)# 测试 docker run -d --name app1 alpine sleep 3600 docker run -d --name app2 alpine sleep 3600 docker exec app1 apk add iputils docker exec app1 ping -c 100 app2 # 结果 rtt min/avg/max/mdev = 0.082/0.125/0.245/0.031 ms 特点:延迟:0.08-0.25ms(容器间)吞吐量:950Mbps优点:隔离性好缺点:性能一般2.Host模式docker run -d --name app-host --network host alpine sleep 3600 docker exec app-host ping -c 100 127.0.0.1 # 结果 rtt min/avg/max/mdev = 0.015/0.022/0.045/0.008 ms特点:延迟:0.015-0.045ms吞吐量:10Gbps优点:性能最好缺点:端口冲突、安全性差3.Overlay模式(跨主机)docker network create -d overlay testnet docker run -d --name app1 --network testnet alpine sleep 3600 # 在另一台主机 docker run -d --name app2 --network testnet alpine sleep 3600 # 测试 docker exec app1 ping -c 100 app2 # 结果 rtt min/avg/max/mdev = 0.245/0.512/1.245/0.156 ms特点:延迟:0.5-30ms(取决于网络)吞吐量:700Mbps(VXLAN损耗)优点:跨主机、K8s支持缺点:性能较差、CPU占用高4.Macvlan模式docker network create -d macvlan \ --subnet=192.168.1.0/24 \ -o parent=eth0 macnet docker run -d --name app1 --network macnet --ip 192.168.1.100 alpine docker exec app1 ping -c 100 192.168.1.101 # 结果 rtt min/avg/max/mdev = 0.052/0.085/0.156/0.022 ms 特点:延迟:0.05-0.15ms吞吐量:950Mbps优点:性能好、独立IP缺点:配置复杂性能对比模式延迟(ms)吞吐量隔离性易用性适用场景Bridge0.08-0.25950Mbps好高开发测试Host0.02-0.0510Gbps差高单体应用Overlay0.5-30700Mbps好中k8s集群Macvlan0.05-0.15950Mbps好低独立IP结论:性能:Host > Macvlan > Bridge > Overlay易用:Bridge = Host > Overlay > Macvlan生产推荐:看场景选择优化方案方案1,内核参数调优cat >> /etc/sysctl.conf <<EOF # TCP优化 net.ipv4.tcp_congestion_control = bbr net.ipv4.tcp_fastopen = 3 net.ipv4.tcp_slow_start_after_idle = 0 # 缓冲区 net.core.rmem_max = 134217728 net.core.wmem_max = 134217728 net.ipv4.tcp_rmem = 4096 87380 134217728 net.ipv4.tcp_wmem = 4096 65536 134217728 # 连接跟踪 net.netfilter.nf_conntrack_max = 262144 # 队列 net.core.netdev_max_backlog = 5000 net.core.somaxconn = 4096 EOF sysctl -p测试结果:{callout color="#EACDD1"}优化前:延迟:30ms吞吐量:942MbpsCPU:45%优化后:延迟:26.5ms (-12%)吞吐量:1.05Gbps (+11%)CPU:42% (-7%){/callout}评价: 效果一般,但零成本,推荐做。方案2,简化iptables规则# 发现问题 iptables -L -n | wc -l # 输出:347行规则! # 每个数据包都要遍历这347条规则 # 优化:禁用Docker的iptables管理 cat > /etc/docker/daemon.json <<EOF { "iptables": false, "ip-forward": true } EOF systemctl restart docker # 手动添加最小规则集 iptables -A FORWARD -i docker0 -o docker0 -j ACCEPT iptables -A FORWARD -i docker0 ! -o docker0 -j ACCEPT # 现在只有50条规则测试结果:{callout color="#EACDD1"}优化前:iptables规则:347条延迟:26.5ms优化后:iptables规则:50条延迟:22.2ms (-16%){/callout}评价: 效果明显,但要小心配置错误导致网络不通。方案3:使用自定义网络# Docker默认bridge性能差 # 自定义网络更好 docker network create \ --driver bridge \ --opt com.docker.network.bridge.name=br-prod \ --opt com.docker.network.driver.mtu=1500 \ prod-network # 使用自定义网络 docker run -d --name app --network prod-network myapp # 可以直接用服务名通信 docker exec app1 ping app2 # 无需IP测试结果:{callout color="#EACDD1"}默认bridge:DNS解析:5-10ms延迟:0.125ms自定义network:DNS解析:1-2ms延迟:0.098ms (-22%){/callout}评价: 简单有效,强烈推荐。方案4:增加conntrack表(效果:解决抖动) 高并发时连接跟踪表会满 # 导致丢包和延迟抖动 echo 262144 > /proc/sys/net/netfilter/nf_conntrack_max # 永久生效 cat >> /etc/sysctl.conf <<EOF net.netfilter.nf_conntrack_max = 262144 net.netfilter.nf_conntrack_buckets = 65536 EOF sysctl -p测试结果(10000并发):{callout color="#EACDD1"}优化前:丢包率:15%延迟:30-80ms(抖动大)优化后:丢包率:0%延迟:22-24ms(稳定){/callout}评价: 高并发场景必做。方案5:使用ipvlan# ipvlan绕过网桥,直接三层路由 docker network create -d ipvlan \ --subnet=192.168.100.0/24 \ -o parent=eth0 \ -o ipvlan_mode=l2 \ ipvlan-net docker run -d --name app --network ipvlan-net --ip 192.168.100.10 myapp测试结果:{callout color="#EACDD1"}Bridge模式:rtt min/avg/max/mdev = 0.082/0.125/0.245/0.031 msipvlan模式:rtt min/avg/max/mdev = 0.045/0.068/0.115/0.018 ms改善:-46%{/callout}评价: 效果很好,但需要管理IP地址。
-
kubectl常用命令 集群信息显示 Kubernetes 版本:kubectl version显示集群信息:kubectl cluster-info列出集群中的所有节点:kubectl get node查看一个具体的节点详情:kubectl describe node <node-name>5.列出所有命名空间:kubectl get namespaces列出所有命名空间中的所有 pod:kubectl get pods --all-namespacesPod信息列出特定命名空间中的 pod:kubectl get pods -n <namespace>查看一个 Pod 详情:kubectl describe pod <pod-name> -n <namespace>查看 Pod 日志:kubectl logs <pod-name> -n <namespace>尾部 Pod 日志:kubectl logs -f <pod-name> -n <namespace>在 pod 中执行命令:kubectl exec -it <pod-name> -n <namespace> -- <command>Pod 亲和性和反亲和性列出 pod 的 pod 亲和性规则:kubectl get pod <pod-name> -n <namespace> -o=jsonpath='{.spec.affinity}'列出 pod 的 pod 反亲和性规则:kubectl get pod <pod-name> -n <namespace> -o=jsonpath='{.spec.affinity.podAntiAffinity}'节点污点 列出节点污点:kubectl describe node <node-name> | grep TaintsPod 优先级和抢占 列出优先级:kubectl get priorityclassesPod 开销 列出 pod 中的开销:kubectl get pod <pod-name> -n <namespace> -o=jsonpath='{.spec.overhead}'Pod 健康检查检查 Pod 准备情况:kubectl get pods <pod-name> -n <namespace> -o jsonpath='{.status.conditions[?(@.type=="Ready")].status}'检查 Pod 事件:kubectl get events -n <namespace> --field-selector involvedObject.name=<pod-name>服务信息Service信息列出命名空间中的所有服务:kubectl get svc -n <namespace>查看一个服务详情:kubectl describe svc <service-name> -n <namespace>更改和验证 Webhook 配置列出变异 webhook 配置:kubectl get mutatingwebhookconfigurations列出验证 Webhook 配置:kubectl get validatingwebhookconfigurationsPod 网络策略 列出命名空间中的 pod 网络策略:kubectl get networkpolicies -n <namespace>部署相关Deployment信息列出命名空间中的所有Deployment:kubectl get deployments -n <namespace>查看一个Deployment详情:kubectl describe deployment <deployment-name> -n <namespace>查看滚动发布状态:kubectl rollout status deployment/<deployment-name> -n <namespace>查看滚动发布历史记录:kubectl rollout history deployment/<deployment-name> -n <namespace>作业和 CronJob列出命名空间中的所有作业:kubectl get jobs -n <namespace>查看一份工作详情:kubectl describe job <job-name> -n <namespace>列出命名空间中的所有 cron 作业:kubectl get cronjobs -n <namespace>查看一个 cron 作业详情:kubectl describe cronjob <cronjob-name> -n <namespace>StatefulSet信息列出命名空间中的所有 StatefulSet:kubectl get statefulsets -n <namespace>查看一个 StatefulSet详情:kubectl describe statefulset <statefulset-name> -n <namespace>ConfigMap 和Secret信息列出命名空间中的 ConfigMap:kubectl get configmaps -n <namespace>查看一个ConfigMap详情:kubectl describe configmap <configmap-name> -n <namespace>列出命名空间中的 Secret:kubectl get secrets -n <namespace>查看一个Secret详情:kubectl describe secret <secret-name> -n <namespace>命名空间信息查看一个命名空间详情:kubectl describe namespace <namespace-name>资源使用情况检查 pod 的资源使用情况:kubectl top pod <pod-name> -n <namespace>检查节点资源使用情况:kubectl top nodes持久卷和持久卷声明列出PV:kubectl get pv查看一个PV详情:kubectl describe pv <pv-name>列出命名空间中的 PVC:kubectl get pvc -n <namespace>查看PVC详情:kubectl describe pvc <pvc-name> -n <namespace>容量信息列出按容量排序的持久卷 (PV):kubectl get pv --sort-by=.spec.capacity.storage查看PV回收策略:kubectl get pv <pv-name> -o=jsonpath='{.spec.persistentVolumeReclaimPolicy}'列出所有存储类别:kubectl get storageclasses存储卷快照列出存储卷快照:kubectl get volumesnapshot -n <namespace>查看存储卷快照详情:kubectl describe volumesnapshot <snapshot-name> -n <namespace>资源反序列化 反序列化并打印 Kubernetes 资源:kubectl get <resource-type> <resource-name> -n <namespace> -o=json网络信息显示命名空间中 Pod 的 IP 地址:kubectl get pods -n <namespace> -o custom-columns=POD:metadata.name,IP:status.podIP --no-headers列出命名空间中的所有网络策略:kubectl get networkpolicies -n <namespace>查看一个网络策略详情:kubectl describe networkpolicy <network-policy-name> -n <namespace>Ingress和服务网格列出命名空间中的所有Ingress:kubectl get ingress -n <namespace>查看一个Ingress详情:kubectl describe ingress <ingress-name> -n <namespace>列出命名空间中的所有 VirtualServices (Istio):kubectl get virtualservices -n <namespace>查看一个 VirtualService (Istio)详情:kubectl describe virtualservice <virtualservice-name> -n <namespace>节点诊断获取特定节点上运行的 Pod 列表:kubectl get pods --field-selector spec.nodeName=<node-name> -n <namespace>Pod 网络故障排除运行网络诊断 Pod(例如 busybox)进行调试:kubectl run -it --rm --restart=Never --image=busybox net-debug-pod -- /bin/bash测试从 Pod 到特定端点的连接:kubectl exec -it <pod-name> -n <namespace> -- curl <endpoint-url>跟踪从一个 Pod 到另一个 Pod 的网络路径:kubectl exec -it <source-pod-name> -n <namespace> -- traceroute <destination-pod-ip>检查 Pod 的 DNS 解析:kubectl exec -it <pod-name> -n <namespace> -- nslookup <domain-name>资源使用情况资源配额和限制列出命名空间中的资源配额:kubectl get resourcequotas -n <namespace>查看一个资源配额详情:kubectl describe resourcequota <resource-quota-name> -n <namespace>自定义资源定义 (CRD)列出命名空间中的自定义资源:kubectl get <custom-resource-name> -n <namespace>查看自定义资源详情:kubectl describe <custom-resource-name> <custom-resource-instance-name> -n <namespace>使用这些命令时,请记住将<namespace>, <pod-name>, <service-name>, <deployment-name>, <statefulset-name>, <configmap-name>, <secret-name>, <namespace-name>, <pv-name>, <pvc-name>, <node-name>, <network-policy-name>, <resource-quota-name>, <custom-resource-name>, 和替换为你的特定值。<custom-resource-instance-name>这些命令应该可以帮助你诊断 Kubernetes 集群以及在其中运行的应用程序。资源伸缩和自动伸缩Deployment伸缩:kubectl scale deployment <deployment-name> --replicas=<replica-count> -n <namespace>设置Deployment的自动伸缩:kubectl autoscale deployment <deployment-name> --min=<min-pods> --max=<max-pods> --cpu-percent=<cpu-percent> -n <namespace>检查水平伸缩器状态:kubectl get hpa -n <namespace>配置和资源验证验证 Kubernetes YAML 文件而不应用它:kubectl apply --dry-run=client -f <yaml-file>验证 pod 的安全上下文和功能:kubectl auth can-i list pods --as=system:serviceaccount:<namespace>:<serviceaccount-name>安全和授权RBAC和安全性列出命名空间中的角色和角色绑定:kubectl get roles,rolebindings -n <namespace>查看角色或角色绑定详情:kubectl describe role <role-name> -n <namespace>Pod 安全策略 (PSP) 列出所有 Pod 安全策略(如果启用):kubectl get psp事件:查看最近的集群事件:kubectl get events --sort-by=.metadata.creationTimestamp按特定命名空间过滤事件:kubectl get events -n <namespace>Pod 安全标准(PodSecurity 准入控制器) 列出 PodSecurityPolicy (PSP) 违规行为:kubectl get psp -A | grep -vE 'NAME|REVIEWED'服务帐户列出命名空间中的服务帐户:kubectl get serviceaccounts -n <namespace>查看一个服务帐户详情:kubectl describe serviceaccount <serviceaccount-name> -n <namespace>清空节点和解除封锁清空节点以进行维护:kubectl drain <node-name> --ignore-daemonsets解除对节点的封锁:kubectl uncordon <node-name>资源清理强制删除 pod(不推荐):kubectl delete pod <pod-name> -n <namespace> --grace-period=0 --force节点故障排除检查节点情况:kubectl describe node <node-name> | grep Conditions -A5列出节点容量和可分配资源:kubectl describe node <node-name> | grep -E "Capacity|Allocatable"临时容器 运行临时调试容器:kubectl debug -it <pod-name> -n <namespace> --image=<debug-image> -- /bin/sh资源指标 获取 Pod 的 CPU 和内存使用情况:kubectl top pod -n <namespace>kuelet诊断 查看节点上的kubelet日志:kubectl logs -n kube-system kubelet-<node-name>使用Telepresence 进行高级调试 使用 Telepresence 调试 pod:telepresence --namespace <namespace> --swap-deployment <pod-name>Kubeconfig 和上下文列出可用的上下文:kubectl config get-contexts切换到不同的上下文:kubectl config use-context <context-name>Pod 中断预算 (PDB)列出命名空间中的所有 PDB:kubectl get pdb -n <namespace>查看一个PDB详情:kubectl describe pdb <pdb-name> -n <namespace>资源锁诊断(如果使用资源锁)列出服务的服务端点:kubectl get endpoints <service-name> -n <namespace>检查 Pod 中的 DNS 配置:kubectl exec -it <pod-name> -n <namespace> -- cat /etc/resolv.conf自定义指标(Prometheus、Grafana) 查询Prometheus指标:用于kubectl port-forward访问Prometheus和Grafana服务来查询自定义指标。节点条件 自定义查询输出:kubectl get nodes -o custom-columns=NODE:.metadata.name,READY:.status.conditions[?(@.type=="Ready")].status -l 'node-role.kubernetes.io/worker='审核日志 检索审核日志(如果启用):检查 Kubernetes 审核日志配置以了解审核日志的位置。节点操作系统详细信息获取节点的操作系统信息:kubectl get node <node-name> -o jsonpath='{.status.nodeInfo.osImage}'这些命令应该涵盖 Kubernetes 中的各种诊断场景。确保将、、等占位符替换为集群和用例的实际值。其他诊断命令
-
PV与PVC之subPath(容器根目录设置) 在某些应用中,同一个Volume可能会被多个Pod或者一个Pod中的多个容器共享。此时可能存在个应用需要不同子目录的需求,可以通过Pod中volumeMounts定义的subPath字段进行设置。通过对subPath的设置,容器将以subPath设置的目录而不是Volume中提供的默认根目录作为根目录。subPath中的路径名称不能以“/”开头,需要使用相对路径的形式。如果希望通过环境变量的形式来设置subPath路径,可以通过subPathExpr字段来实现。subPath和subPathExpr字段是互斥的,不能同时使用。示例{tabs}{tabs-pane label="subPath"}--- apiVersion: v1 kind: Pod metadata: name: mysql spec: containers: - name: mysql image: mysql env: - name: MYSQL_ROOT_PASSWORD volue: "rootpassword" volumeMounts: - mountPath: /var/lib/mysql name: site-data subPath: mysql - name: php image: php volumeMounts: - mountPath: /var/www/html name: site-data subPath: html volumes: - name: site-data persitentVolumeClaim: claimName: site-data-pvc{/tabs-pane}{tabs-pane label="subPathExpr"}--- apiVersion: v1 kind: Pod metadata: name: pod1 spec: containers: - name: containers1 image: busybox command: ["sh","-c","sleep 6000"] env: - name: POD_NAME volueFrom: fieldRef: apiVersion: v1 FilePath: metadata.name volumeMounts: - name: workdir1 mountPath: /logs subPathExpr: $(POD_NAME) restartPolicy: Never volumes: - name: workdir1 hostpath: path: /var/log/pods {/tabs-pane}{/tabs}
-
集群存储之PV与PVC PVPV:Persistent Volume 持久卷。资源提供者,根据集群的基础设施变化而变化,由集群管理员进行配置管理。PV将存储定义为一种容器应用可以使用的资源。PV由管理员创建和配置,它与存储资源提供者的具体实现直接相关。不同提供者提供的PV类型包括NFS、iSCSI、RBD或者由公有云提供的共享存储。PV与普通的临时卷一样,也是通过插件机制进行实现的,只是PV的生命周期独立于使用它的Pod。PV并不直接属于某个Pod。如果某个Pod想要使用PV,需要使用PVC来完成申请。随后Kubernetes会完成从PVC到PV的绑定。之后被绑定的PV就可以被申请的Pod使用了。一个PV只能被一个PVC绑定,被绑定的PV不能再被其他PVC绑定。 PART.01 PV详解 PV作为对存储资源的定义,主要涉及存储能力,访问模式,存储类型,回收策略,后端存储类型等关键信息的设置。不同类型的PV是以不同的插件进行设计和实现的,主要包括以下几类:CSI:CSI容器存储借口,由存储资源提供者提供驱动程序和存储管理程序FC(Fibre channel):光纤存储设备hostPath:宿主机目录,仅供单Node测试iSCSI:iSCSI存储设备Local:本地持久化存储NFS:基于NFS协议的网络文件系统# 示例 apiVersion:v1 kind: PersistentVolume metadata: name: pv1 spec: capacity: storage: 5Gi volumeMode: Filesystem accesModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle storageOptions: - hard - nfsvers=4.1 nfs: path: /tmp server: 10.15.55.55 存储容量(capacity)存储容量用于描述存储的容量,目前仅支持对存储空间的设置(storage=XX)。存储卷模式(volumeMode)可选性只有两个:Filesystem(文件系统,默认值)和Block(块设备)。文件系统模式的PV将以目录(Directory)形式被挂载到Pod内。访问模式ReadWriteOnce(RWO):读写权限,只能被单个Node挂载(单用户读写)ReadOnlyMany(ROX):只读权限,允许被多个Node挂载(多用户只读)ReadWriteMany(RWX):读写权限,允许被多个Node挂载(多用户读写)ReadWriteOncePod(RWOP):可以被单个Pod以读写方式挂载,仅支持CSI存储卷,用于集群中只有一个Pod时以读写方式使用这种模式的PVC。某些PV可能同时支持多种访问模式,但PV在挂载时只能使用一种访问模式,多种访问模式不能同时生效。节点亲和性(nodeAffinity)PV可以通过设置节点亲和性来实现只能通过某些Node访问Valume,这可以在PV定义的nodeAffinity字段中进行设置。使用这些Volume的Pod将被调度到满足亲和性要求的Node上。大部分存储驱动提供的volume都已自动完成亲和性的设置,通常无需用户手动设置。对于Local类型的PV,需要手动设置。apiVersion: v1 kind: PersistentVolume metadata: name: local-pv spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete storageClassName: local-storage local: path: /mnt/disks/ssd1 nodeAffinity: required: nodeSelectorterms: - matchExpressions: - key: kubernetes.io/hostname operator: In volues: - my-nodePV生命周期Available:可用状态,还未与某个PVC绑定Bound:以与某个PVC绑定Released:与之绑定的PVC已被删除,但未完成资源回收,不能被其他PVC使用Failed:自动资源回收失败 PART.01 PVC详解 PVC:PersistentVolumeClaim 持久卷声明。资源的使用着,根据业务的需求变化来配置,用户无需知道PV的技术细节,只需要声明你需要什么样的资源资源即可。apiVersion: v1 kind: PersistentVolumeClaim metadata: name: myclaim spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 8Gi storageClassName: slow selector: matchLabels: release: "stable" matchExpressions: - { key: environment, operator: In, values: [dev] } 说明resources:资源请求,描述对存储资源的请求,通过resources.requests.storage字段设置需求的存储空间的大小accessModes:访问模式,PVC也可以设置访问模式,用于描述用户应用对存储资源的访问权限volumeMode:存储卷模式,用于描述希望使用的PV存储卷模式,包括文件系统和块设备。PVC设置的存储卷模式最好与PV存储卷模式相同,以实现绑定。如果不同可能会出现无法绑定的结果。selector:PV选择条件,通过设置Label Selector,可以使PVC对于系统中已经存在的各种PV进行筛选。系统将根据标签选出合适的PV与该PVC进行绑定。对于选择条件,可以通过matchLabels和matchExpressions进行设置。如果两个字段都已设置,则Selector要同时满足才能完成匹配。Clas:存储类别,在定义PVC时可以设定需要的后端存储类别(通过storageClassName字段进行指定),以减少对后端存储特性的详细信息的依赖。只有设置了Class的PV才能被系统筛选出来,与该PV进行绑定。PVC也可以不设置Class需求,如果storageClassName字段的值被设置为空(storageClassName=""),则表示该PVC不需求特定的Class,系统只选择未设定Class的PV与之绑定。PVC也可以完成不设置storageClassName字段,此时将根据系统是否启用了名为DefaultStorageClass的Admission Controller进行相应的操作。{mtitle title="PV和PVC的工作原"/}1.资源供应Kubernetes支持两种资源供应模式:静态(static)和动态(Dynamic)模式。资源供应的结果就是将适合的PV与PVC成功绑定。静态模式:集群管理员预先创建若干PV,在PV的定义中能够体现存储资源的特征。动态模式:集群管理员无需预先创建PV,而是通过StorageClass的设置对后端存储资源进行描述,标记存储的类型和特征。用户通过创建的PVC对存储类型进行申请。之后,StorageClass中的驱动提供者将自动完成PV的创建工作,并将创建出的PV与PVC进行绑定。如果PVC声明的Class为空,则说明PVC不适用动态模式。Kubernetes支持设置集群范围内默认的StorageClass,为用户创建的PVC设置一个默认的存储类StrongClass。2.资源绑定在用户定义好PVC后,系统将根据PVC对存储资源的请求(存储空间和访问模式),在已存在的PV中选择一个满足PVC要求的PV。一旦找到,就将该PV与用户定义的PVC进行绑定,用户的应用就可以使用这个PVC了。如果系统中没有满足PVC要求的PV,那么PVC会无限期处在pending状态,直到系统为其创建了一个满足要求的PV。PV一旦与某个PVC完成绑定,就会被这个PVC独占,不能再与其他的PVC绑定。PVC与PV的绑定关系是一对一的,不会存在一对多的情况。但是同一个PVC可以被多个Pod同时挂载(应用需要处理完成多个进程访问同一个存储的问题)。如果PVC申请的存储空间比PV拥有的存储空间少,则整个PV的空间都能为PVC所用。但是这可能造成一定的资源浪费。如果资源供应使用的是动态模式,那么系统在为PVC找到合适的StorageClass后,将自动创建一个PV并完成与PVC的绑定。3.资源使用当Pod需要使用存储资源时,需要在Volume的定义中引用PVC类型的Volume,将PVC挂载到容器内的某个路径下进行使用。Volume的类型字段为“persistentVolumeClaim”。Pod在被挂载了PVC后,就可以使用存储资源了。4.资源回收用户使用完存储资源后,可以删除PVC。与该PVC绑定的PV会被标记为“已释放”,但它还不能立刻与其他PVC绑定。Pod在该PVC中生成的数据可能还被保留在PV对应的存储设备上。只有在清楚了这些数据后,才能再次使用该PV。PV的回收策略Retain(保留)Delete(删除)Retain策略 表示在删除PVC后,与之绑定的PV不会被删除,仅被标记为已释放(released)。PV中的数据仍然存在,在清空数据之前不能被新的PVC使用,需要管理员手动清理之后才能继续使用。清理步骤:删除PV资源对象,此时与该PV关联的某些外部存储资源提供者的后端存储资产(Asset)中的数据仍然存在。手动清理PV后端存储资产中的数据。手动删除后端存储资产。如果希望重用该资产,可以创建一个新的PV与之关联。Delete策略 表示自动删除PV资源对象和相关后端存储资产,同时会删除与该PV关联的后端存储资产。但并不是所有类型的存储资源都支持Delete策略。通过动态供应机制创建的PV将继承StorageClass的回收策略,默认为delete策略。管理员应该基于用户的需求来设置StorageClass的回收策略,或者在创建出PV后手动更新其回收策略。存储对象保护机制存储资源(PV、PVC)相对于容器应用(Pod)是可以独立管理的资源,可以单独将其删除。在执行删除操作时,系统会检测存储资源当前是否正在被使用,如果仍被使用,则相关资源对象的删除操作会被推迟,直到没有被使用才会执行删除操作。这样可以确保资源在仍被使用的情况下,不会被直接删除而导致数据丢失,这个机制被称为使用中的存储对象的保护机制(Storage Object in Use Protection)。对于PVC的删除操作将等到使用它的Pod被删除后再执行。当用户删除一个正在使用中的PVC时,PVC资源对象不会被立即立即删除,查看PVC资源对象的状态,可以看到其为“Terminating”,以及系统为其设置的Finalizer为“kubernetes.io/pvc-protection”,说明PVC资源对象处于被保护状态。对PV的删除操作将等到绑定的PVC删除之后再执行。当用户删除一个仍被PVC绑定的PV时,PV对象不会立即被删除,查看PV资源对象的状态,可以看到其为“Terminating”,以及系统为其设置的Finalizer为“kubernetes.io/pv-protection”,说明PV资源对象处于被保护状态。总的来说,PV与PVC的删除顺序是这样的:先删除正在使用PVC的Pod,再删除PVC,最后删除PV。